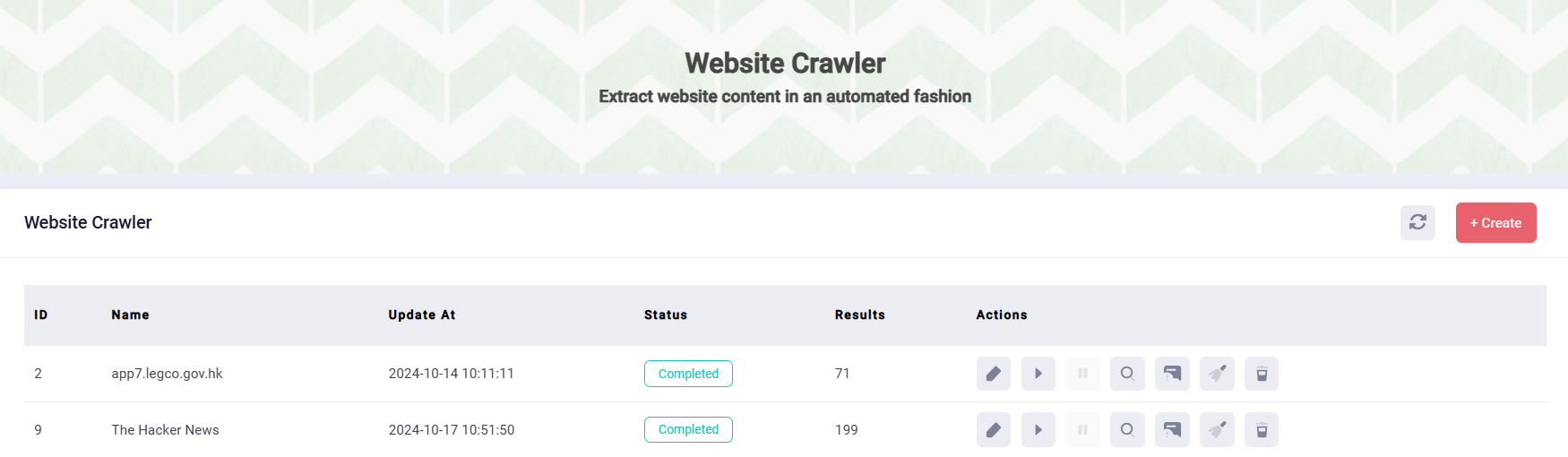
Web Data Extraction Solution
Demo 1
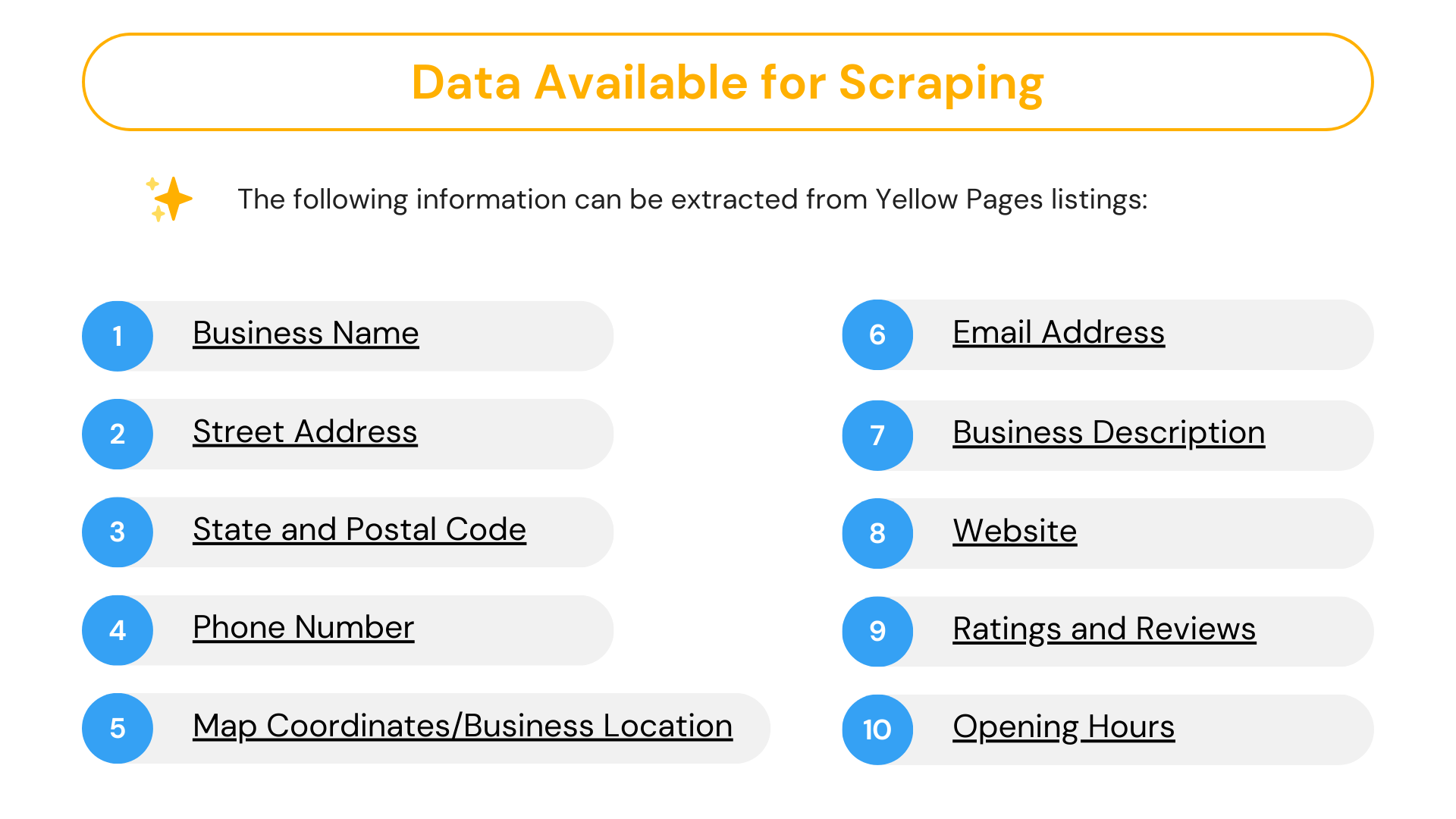
Yellow Pages Crawling



Steps of Using Website Crawler
to Scrape Yellow Pages
Here’s how to use Website Crawler to extract data from Yellow Pages listing:
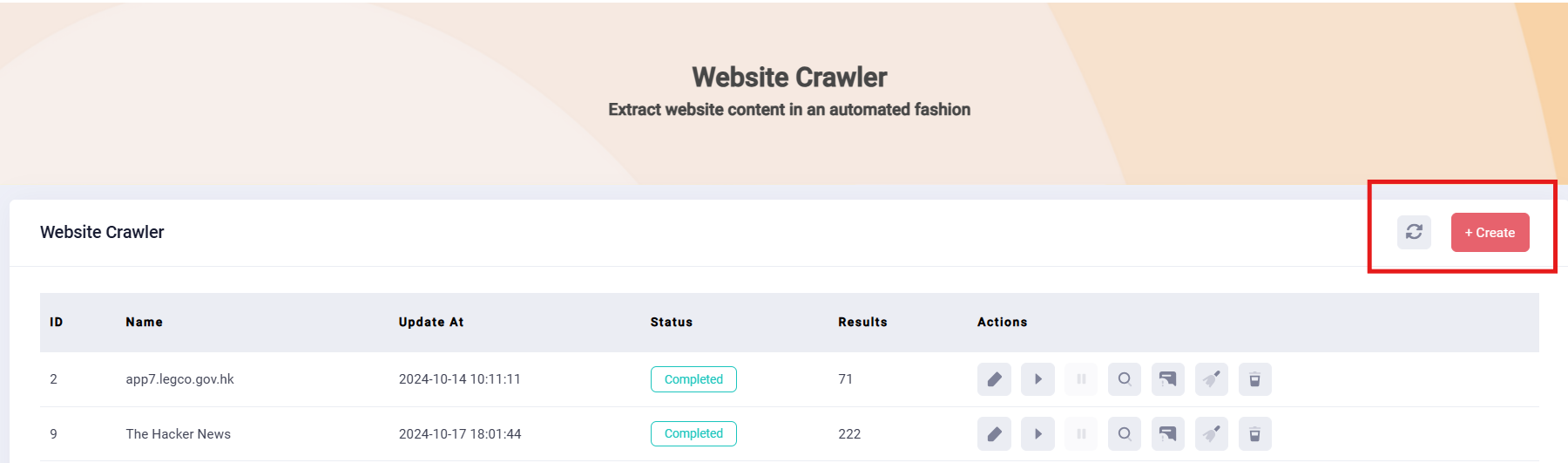
1. Visit DataCanva website: Begin by visiting DataCanva website, then select the Web Data Extraction feature.
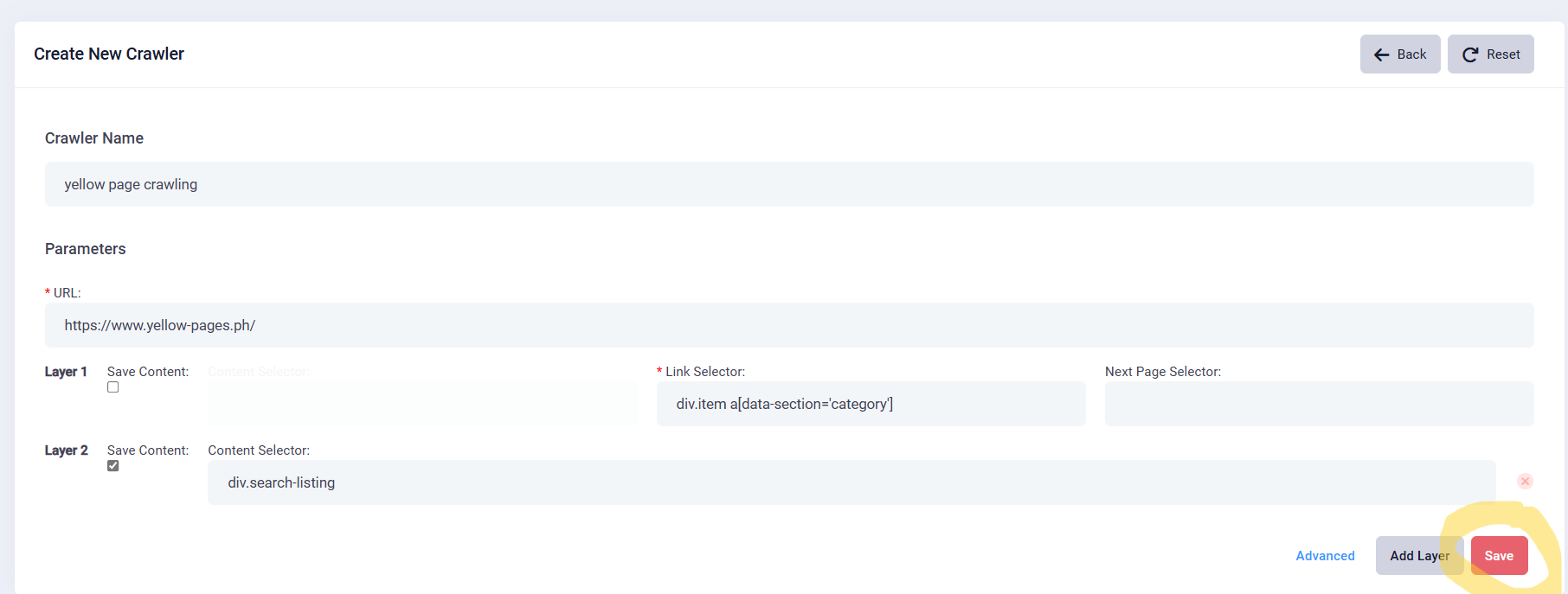
2. Create a new crawler : Click the “Create” button to kick off the process. Fill in the mandatory column accordingly.
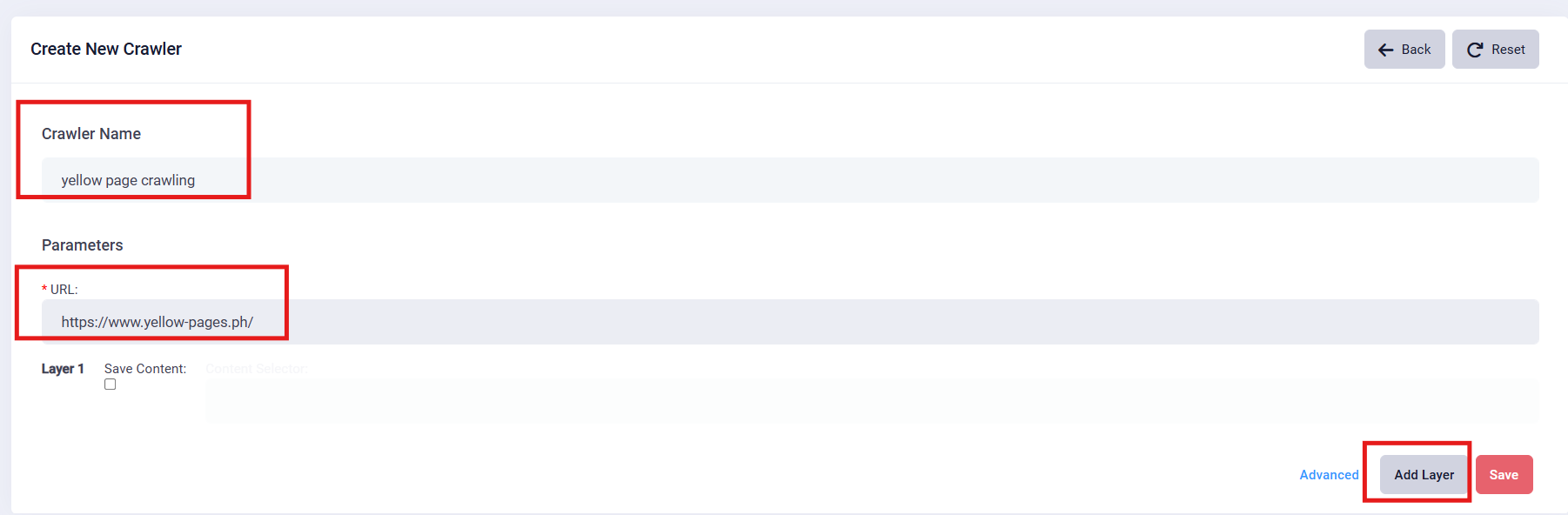
3. Add layers: For example, if the data you want to select is on the next page, you can simply add one layer.
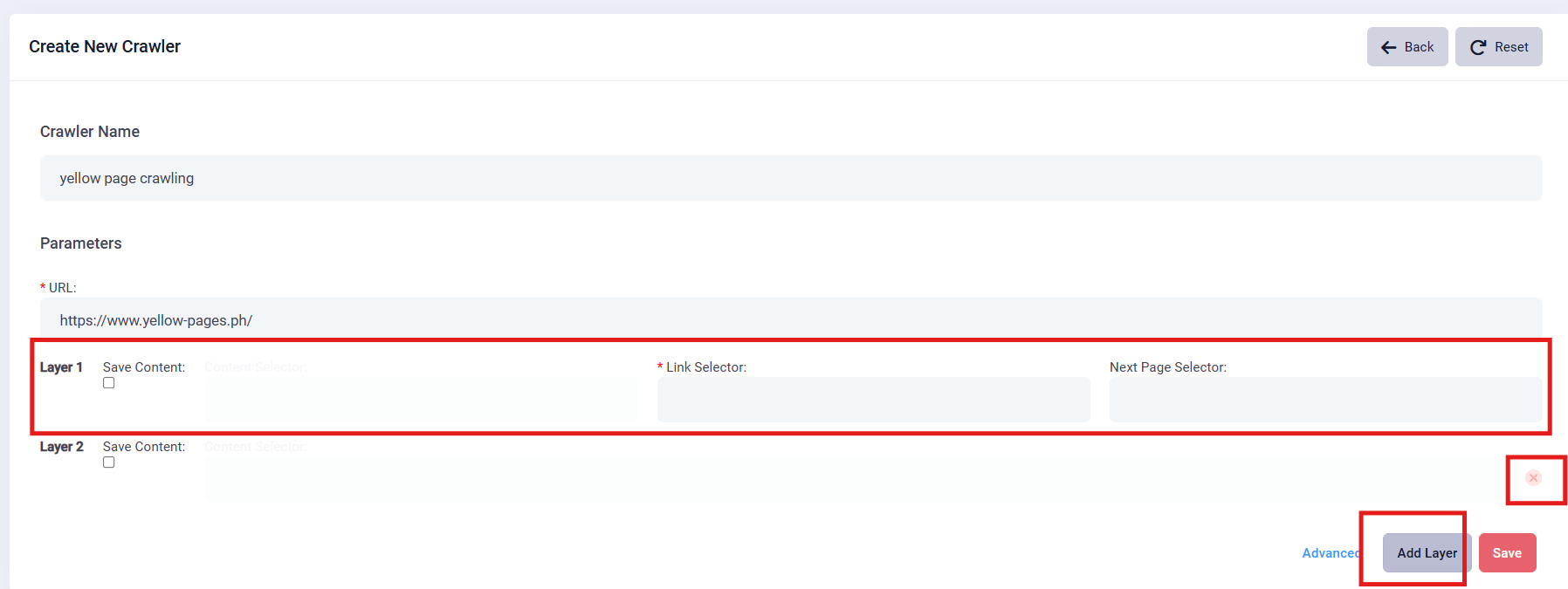
4. Select Data: As you hover over various elements on the page, right click the pop-up window, click the “inspect” and the name of the data will be highlighted. Click on the relevant text to identify the specific layer name. Below example shows the first layer selector and respective fill-in content. In this case: (div.item a[data-section='category'])


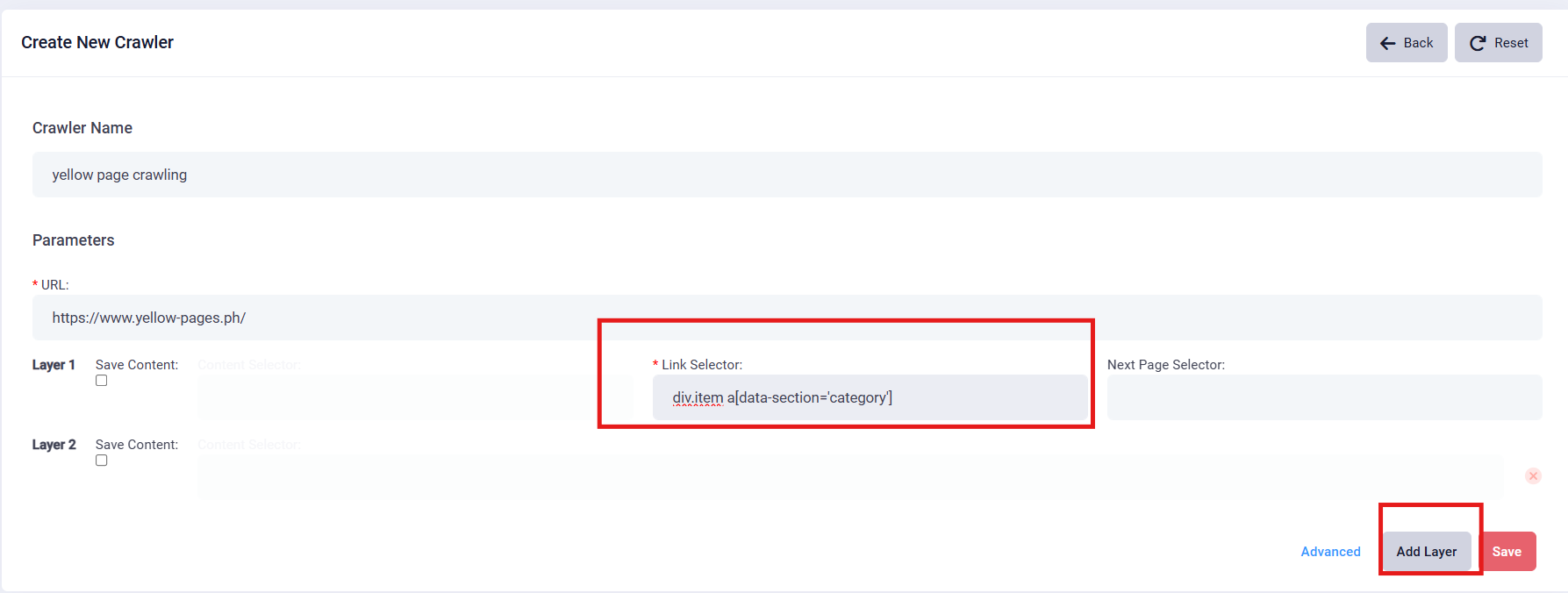
5. Select Data: if you want to save this yellow page's content, you can click the checkbox below the “Save Content”, and the grey fill-in area will show up.
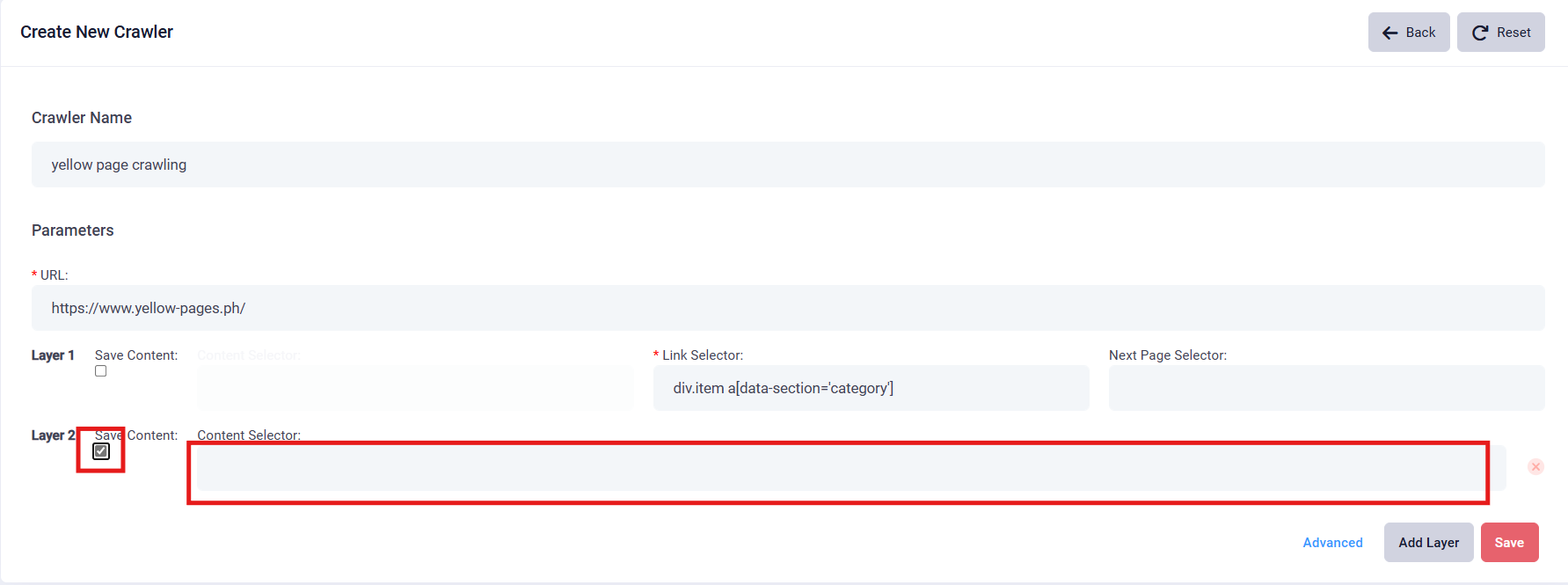
6. Select Second Layer Data: if you want to extract this yellow pages' content, click the “inspect” and the name of the data will be highlighted. Click on the relevant text to identify the specific layer name. Below example shows the second layer selector and respective fill-in content. In this case: (div.search-listing)
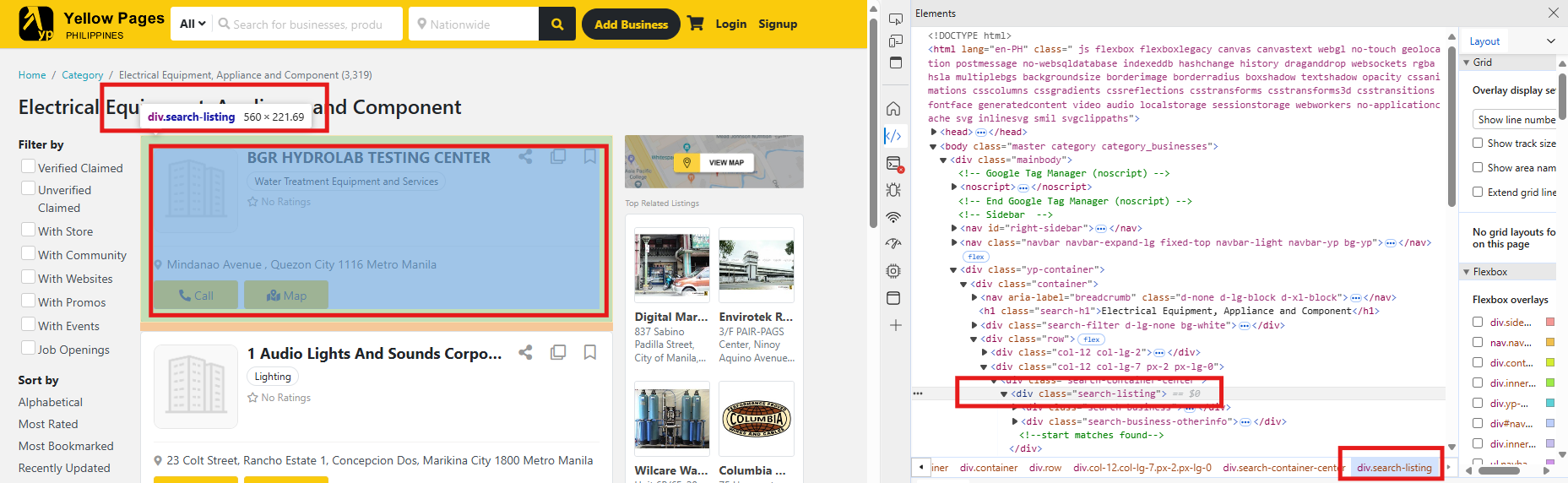
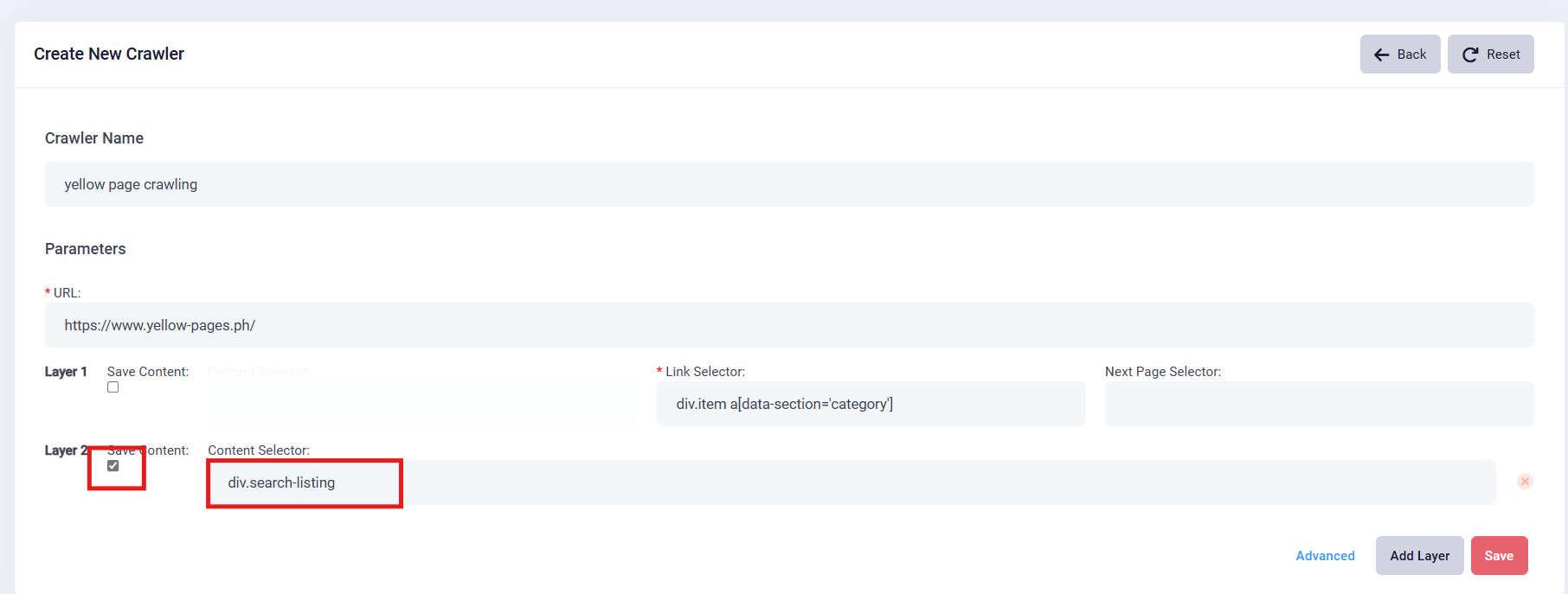
7. Finalize Crawler Creation: Once you’ve finished the setting, click the "Save" button. You can save this crawler for future use. This crawler will show on the Website Crawler list.
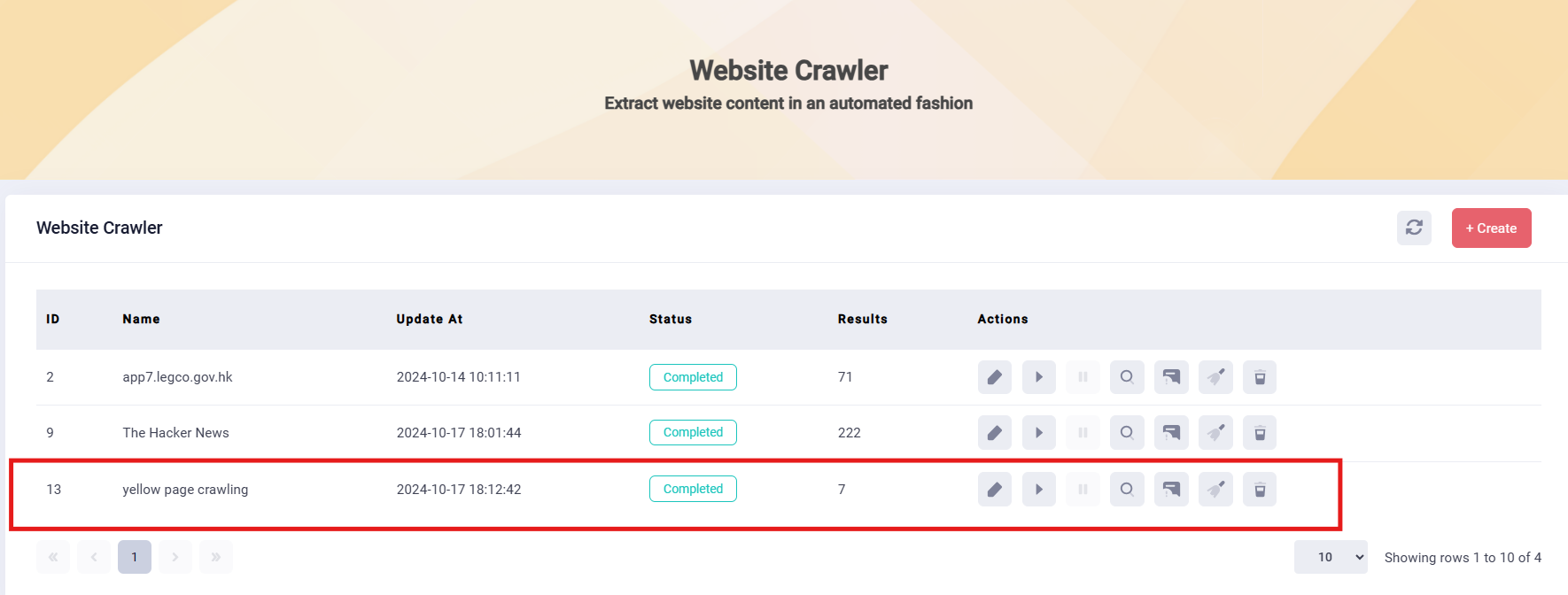
7. Start Scraping: To begin data extraction, go to the Website Crawler list, select the crawler you want to run. Click the "Start" button. The Crawler process will run automatically; the "Status" will show the process.
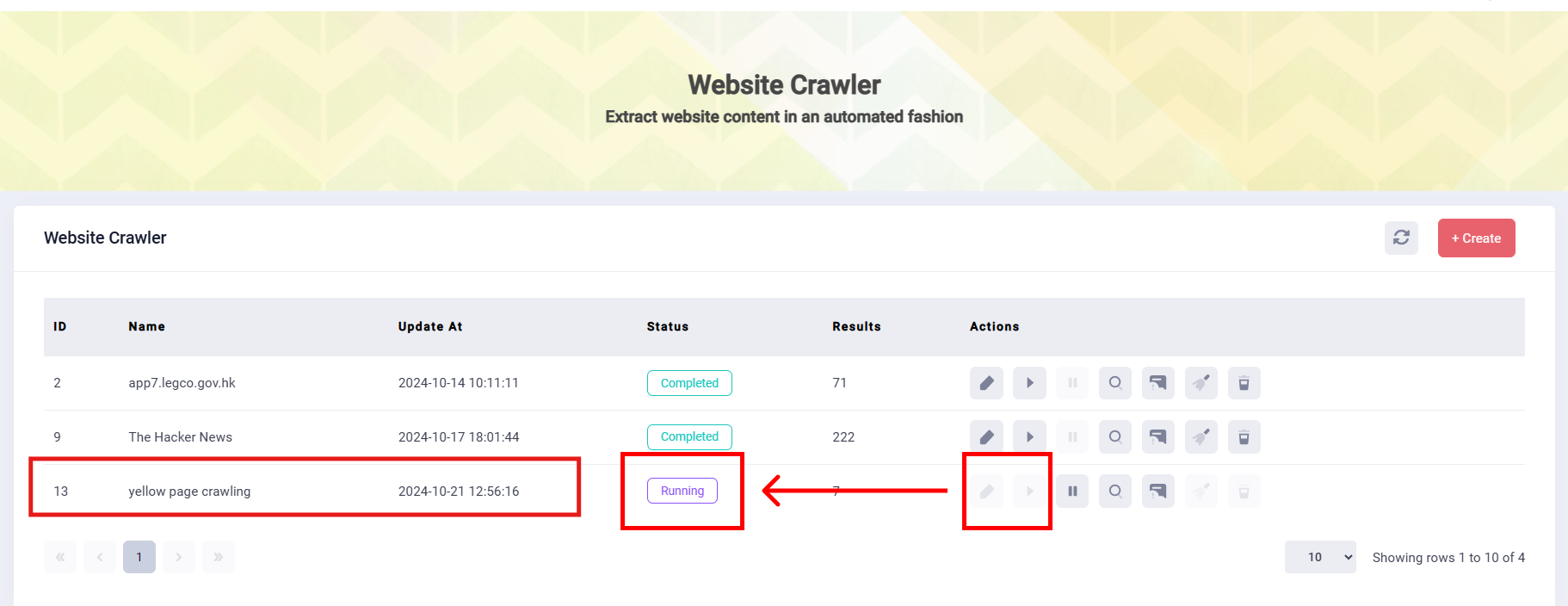
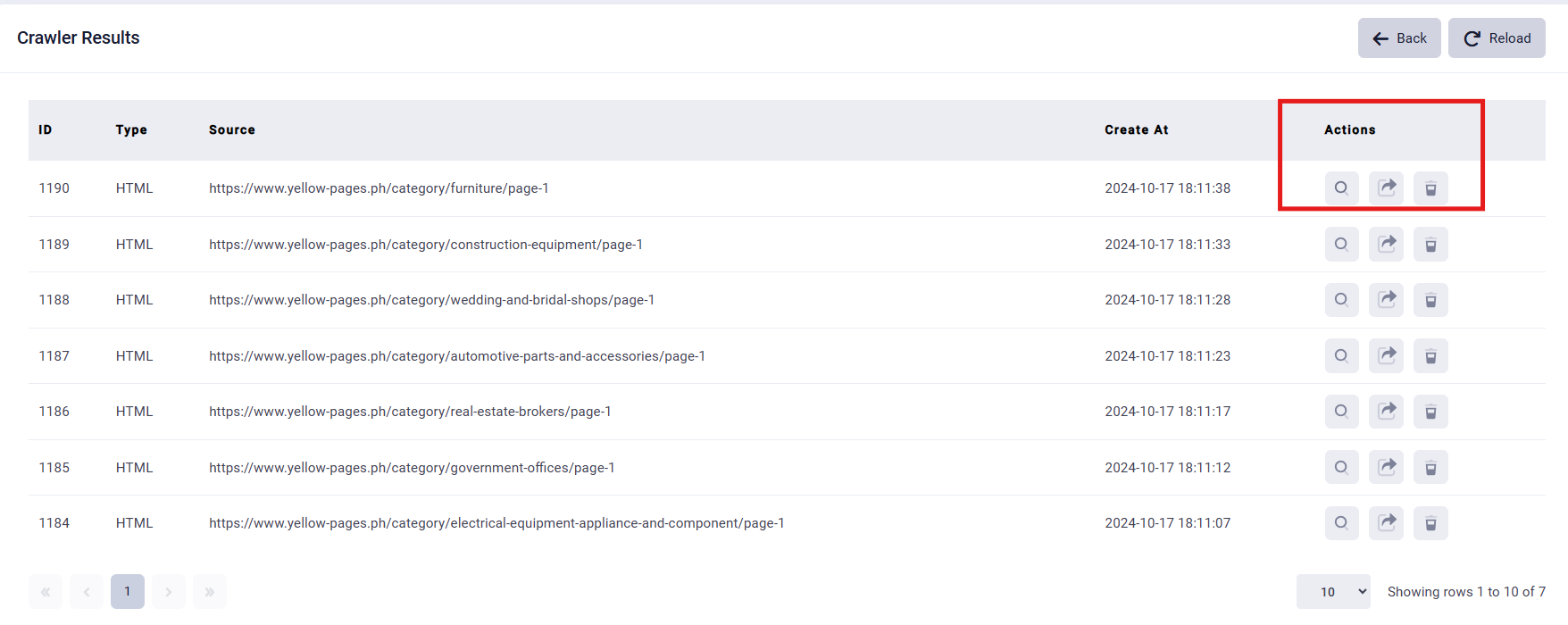
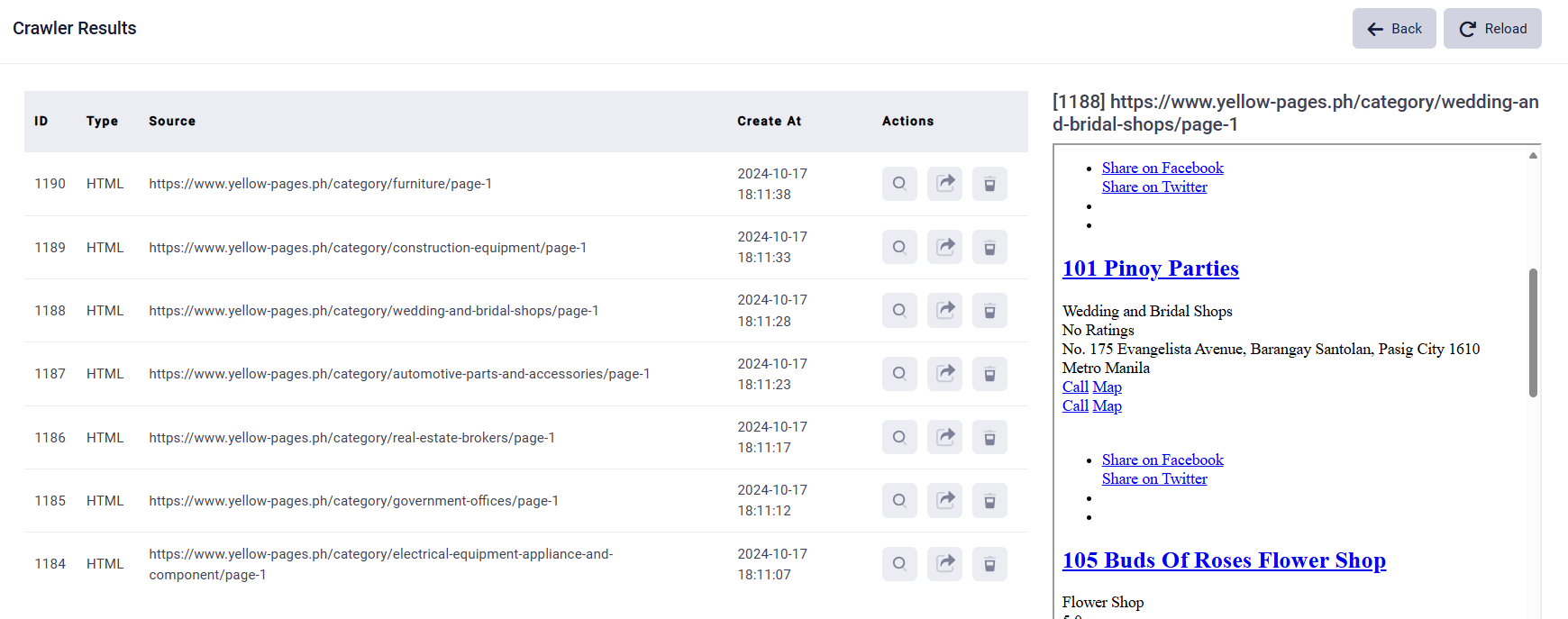
8. Data Collection: Once the Status shows “completed”, you can click the “search” button to see all the result sets. And you can click the “search” button of one result record, the extracted data will show on the right part of the webpage.