Web Data Extraction Solution Demo 2
How to Extract Data from News Websites
The demand for scraping news websites is growing rapidly, can be beneficial for several scenarios like:

With our website crawler, individuals and organizations can efficiently gather, analyze, and utilize news data to enhance their decision-making, content creation, and overall understanding of current events. Next example will show you how the Website Crawler scrapes a news website.
1. Randomly select a news website
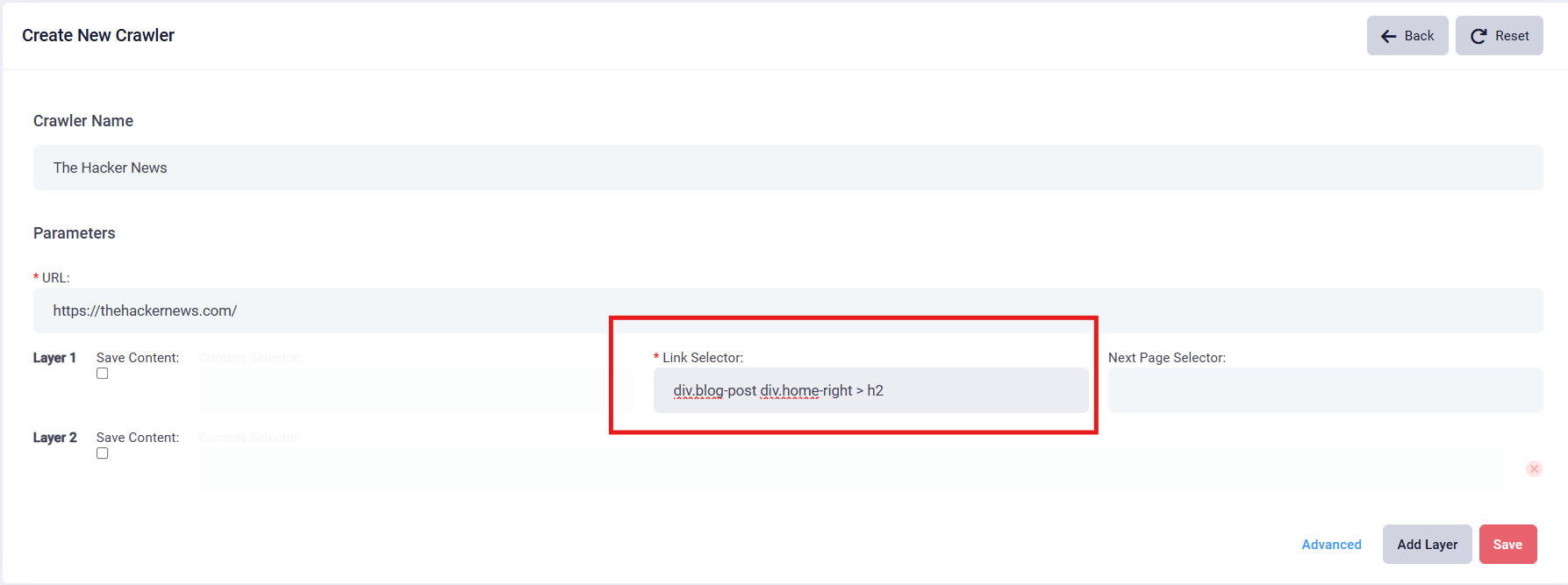
2. Create a crawler for a news website. Fill in the form as the Crawler required.

3.Right click the website that you want to crawl. Then on the pop-up window, click "Inspect". The following page will be popped up.
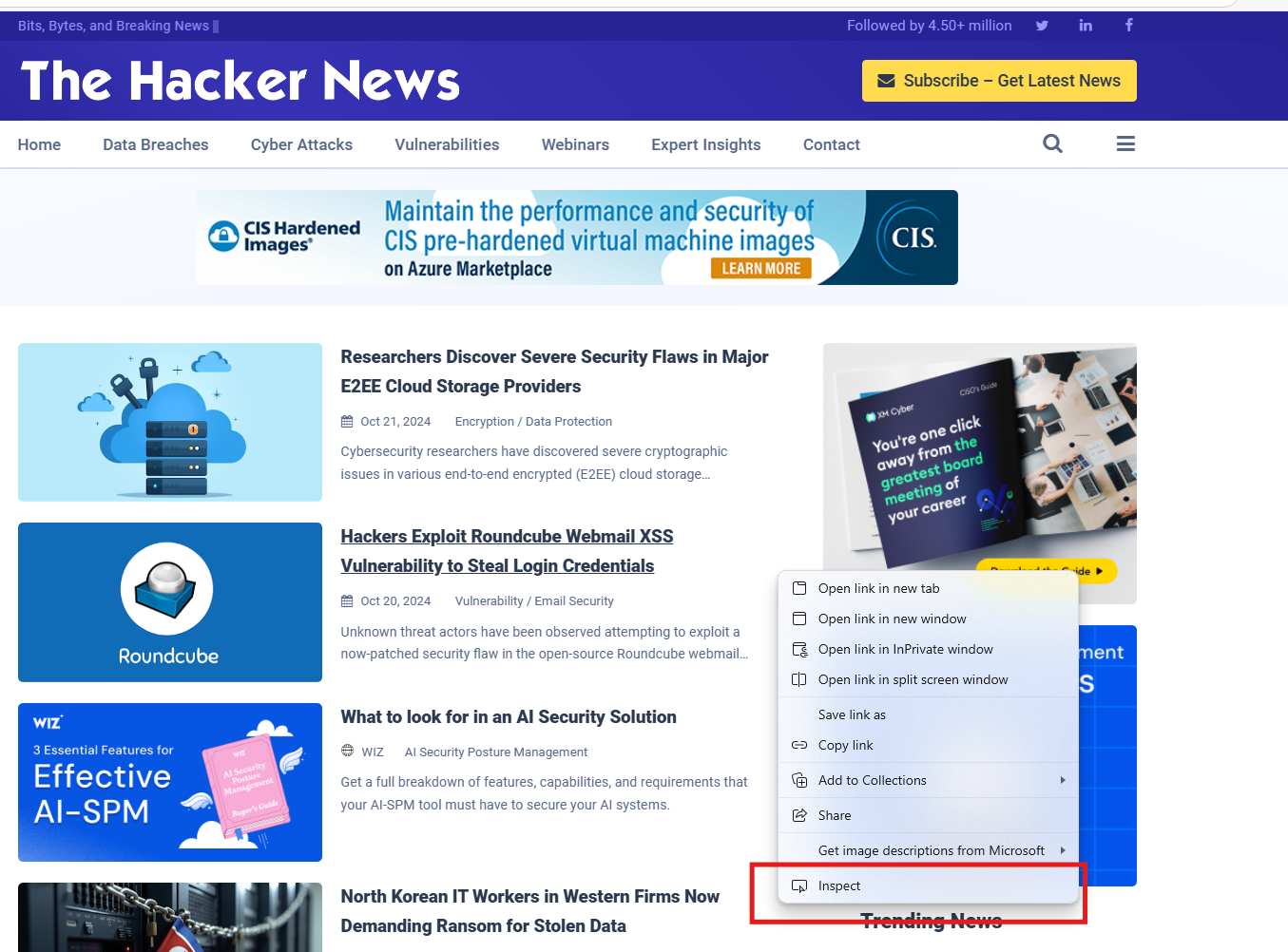
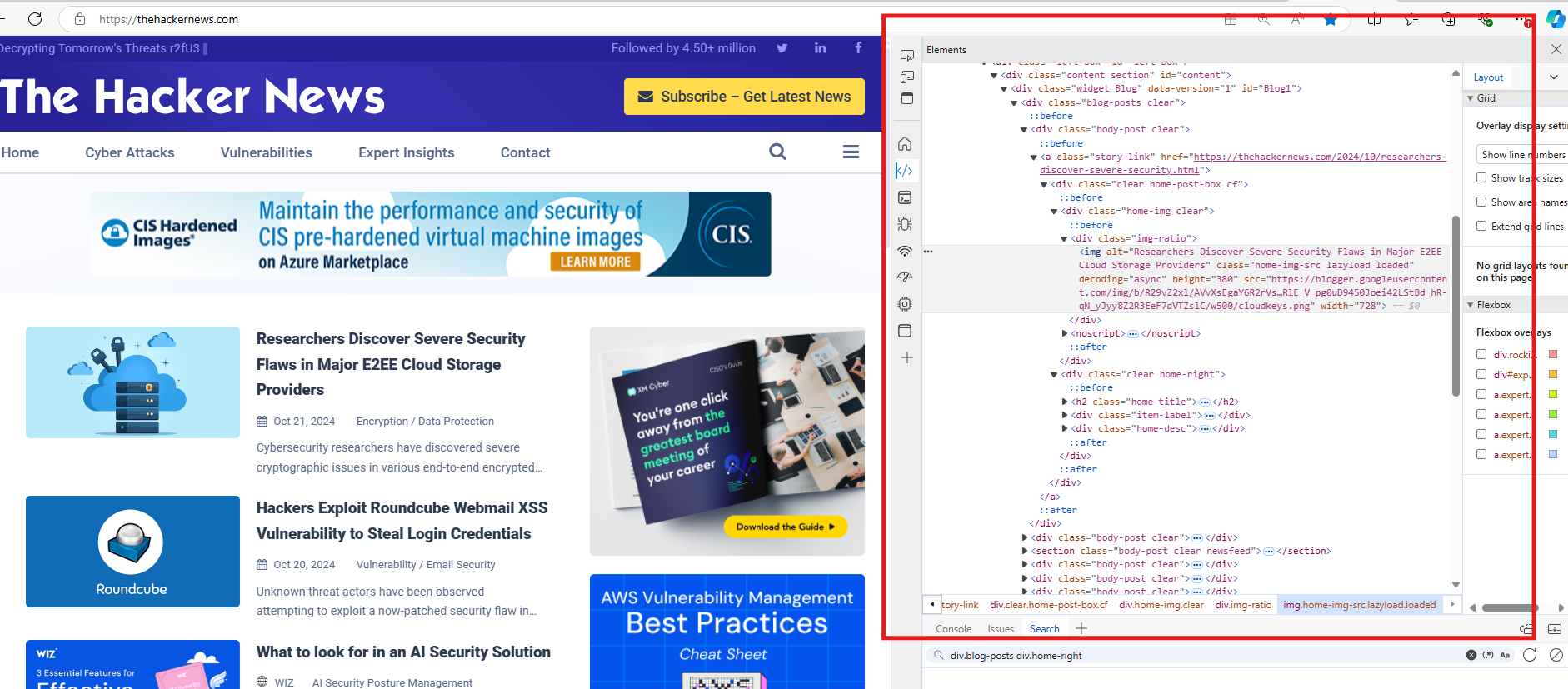
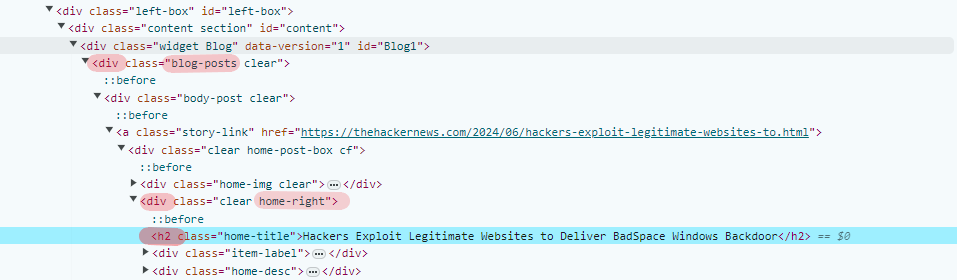
4. In this page, you can find the path of your ideal Link Selector, in this case: (div.blog-post div.home-right > h2). Fill in the path in the Link Selector box.
5. You can also fill in the Next Page Selector if needed. Go to the website and right click the page button (It is usually located on the bottom of the website). And click "Inspect".
6. The next page will be popped up.

7. After getting the ID of it, you can fill in the Next Page Selector box, in this case: (Blog1_blog-pager-older-link)
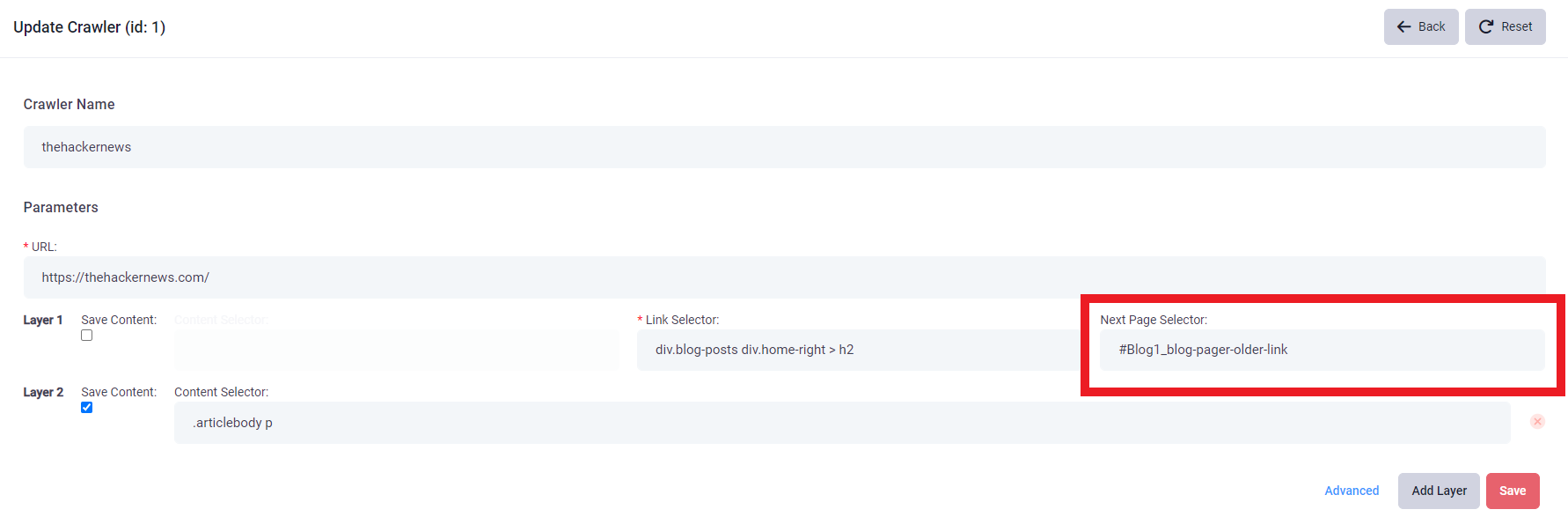
8. If you want to save contents in a layer, tick the Save Content box and fill in the Content Selector. And go to the website and right click the content that you need and click "Inspect".
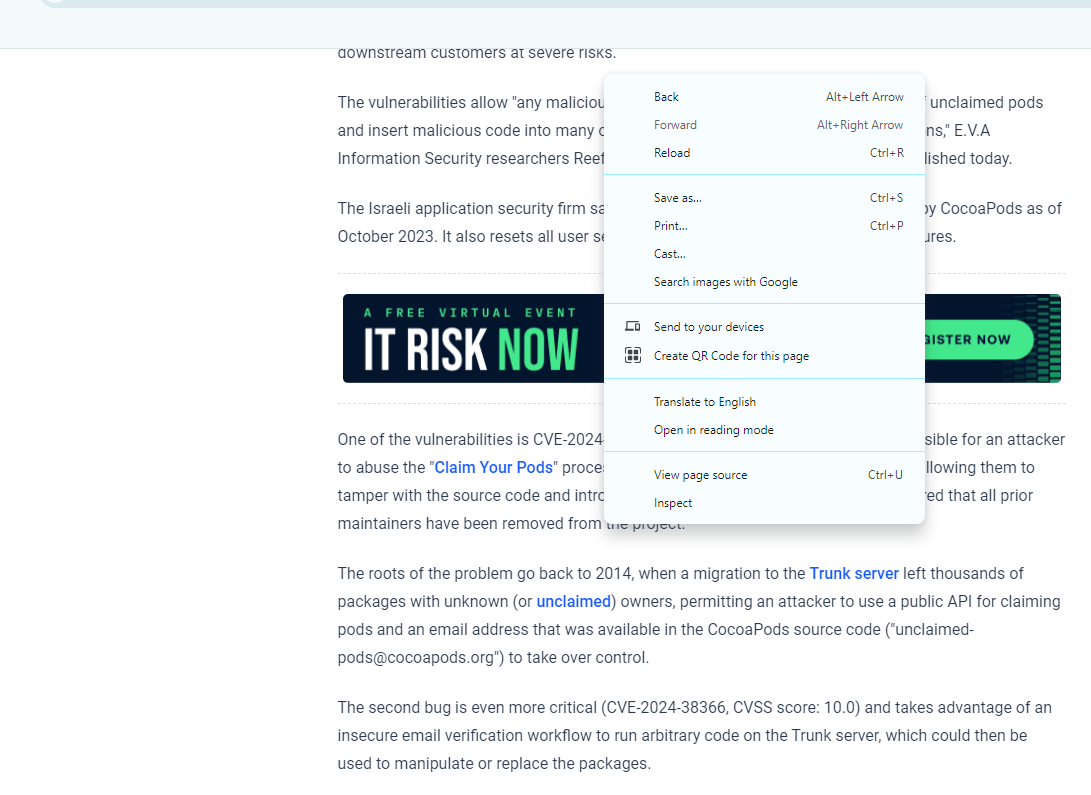
9. Then a page that is similar to the following page will be popped up.

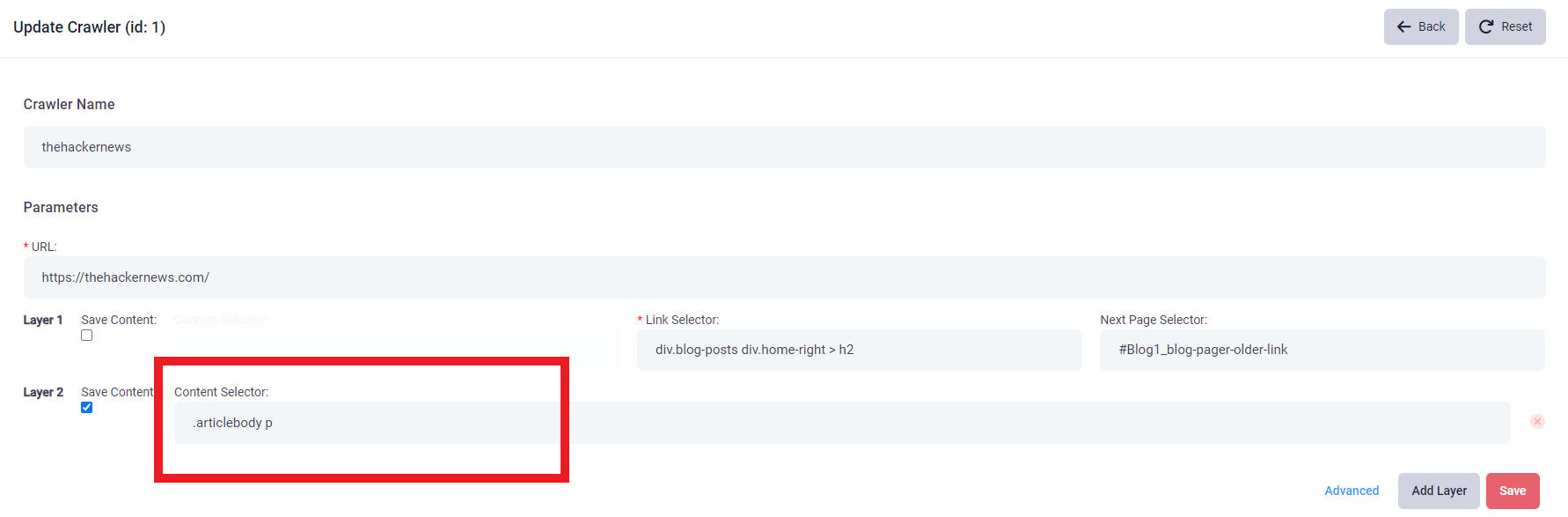
10. After getting the path of it, you can fill in the Content Selector box. Then click the ”Save” button. A news website crawler has been created. You can find it on the Website Crawler lists.
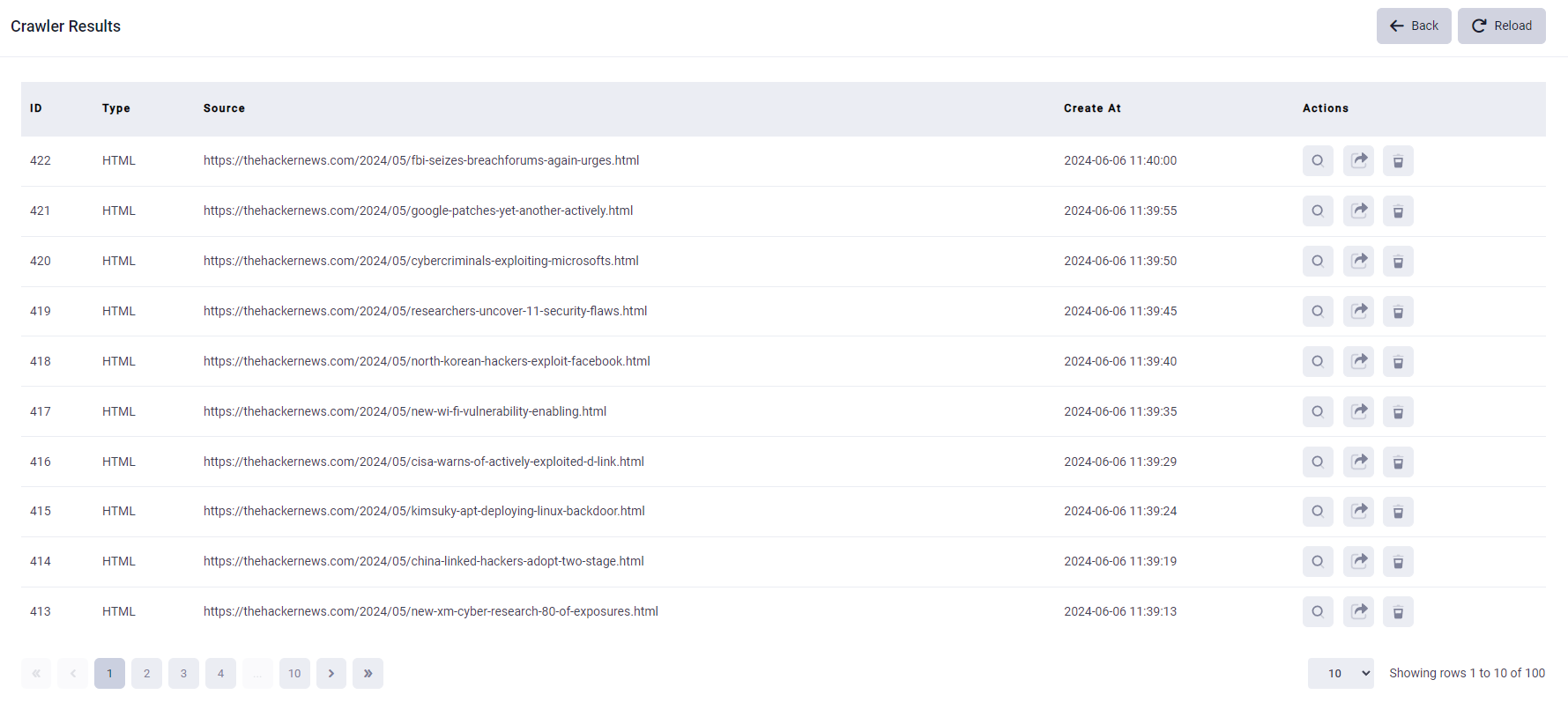
11. You can click the “start” button to run this crawler like the below picture shows.
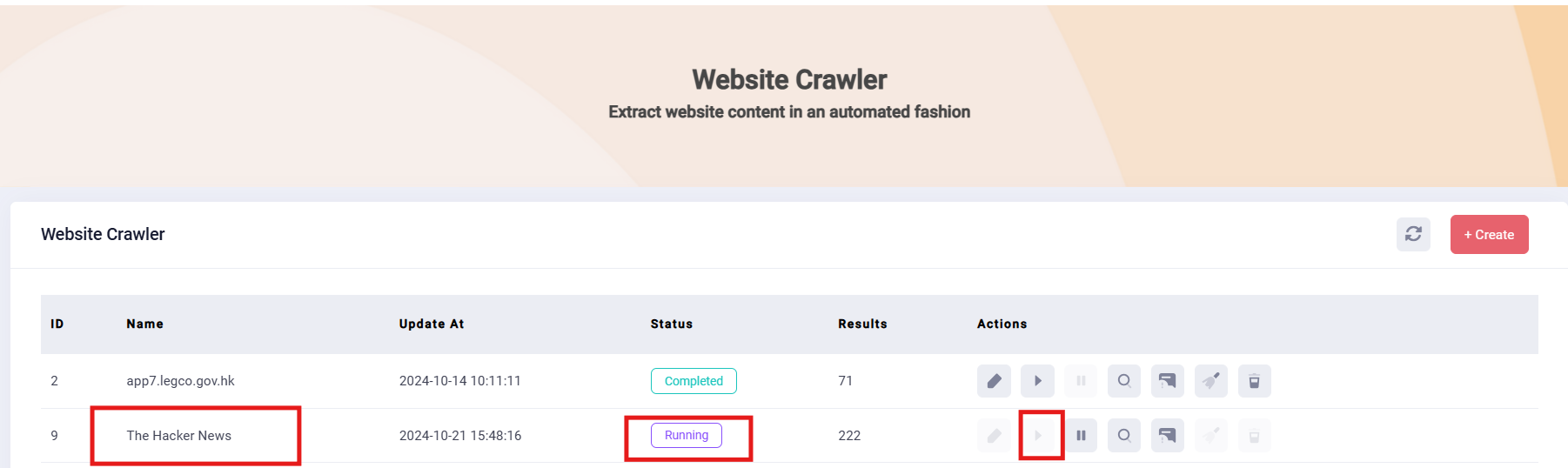
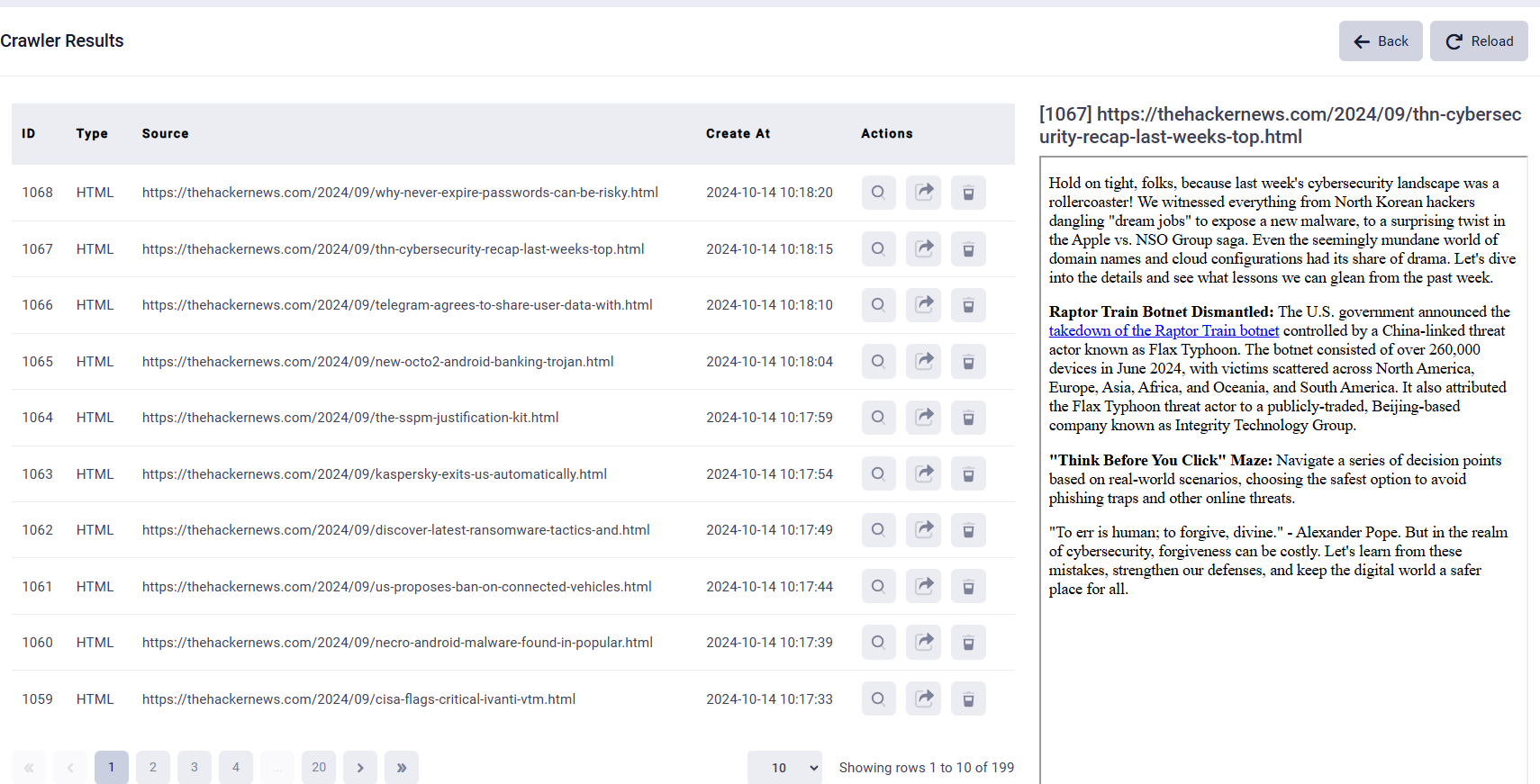
12. After the crawler process is complete, the status will turn to Completed. You can click the button to view the result of the crawler. You will proceed to the following page. Click the “search” icon, you can see the result of the crawler.