Data Automation Platform
DataCanva

Various Disconnected Data
Customers generate data across various touchpoints, often in different formats and from multiple sources. Traditionally, there hasn't been a unified repository for holistic access and analysis of this data.

Customer Query and Segmentation
Blending and transforming data, as well as executing queries, typically require technical expertise. Even simple queries can be delayed, as they often rely on IT specialists to create hard-coded scripts for business users.

Handling Real-Time Updates
Data is generated continuously, and faster processing can enhance customer engagement. Traditionally, customer data has been processed in batches, leading to unnecessary delays in certain situations.
Incorporating Custom Programs
It is increasingly common to integrate data from affiliate sources or the internet to inform better business decisions. Traditionally, only first-party data has been manageable through standardized models.
Core Functions
Dashboard
Entity Metrics
Pipeline Metrics

Execution Timeline
Recent Changes
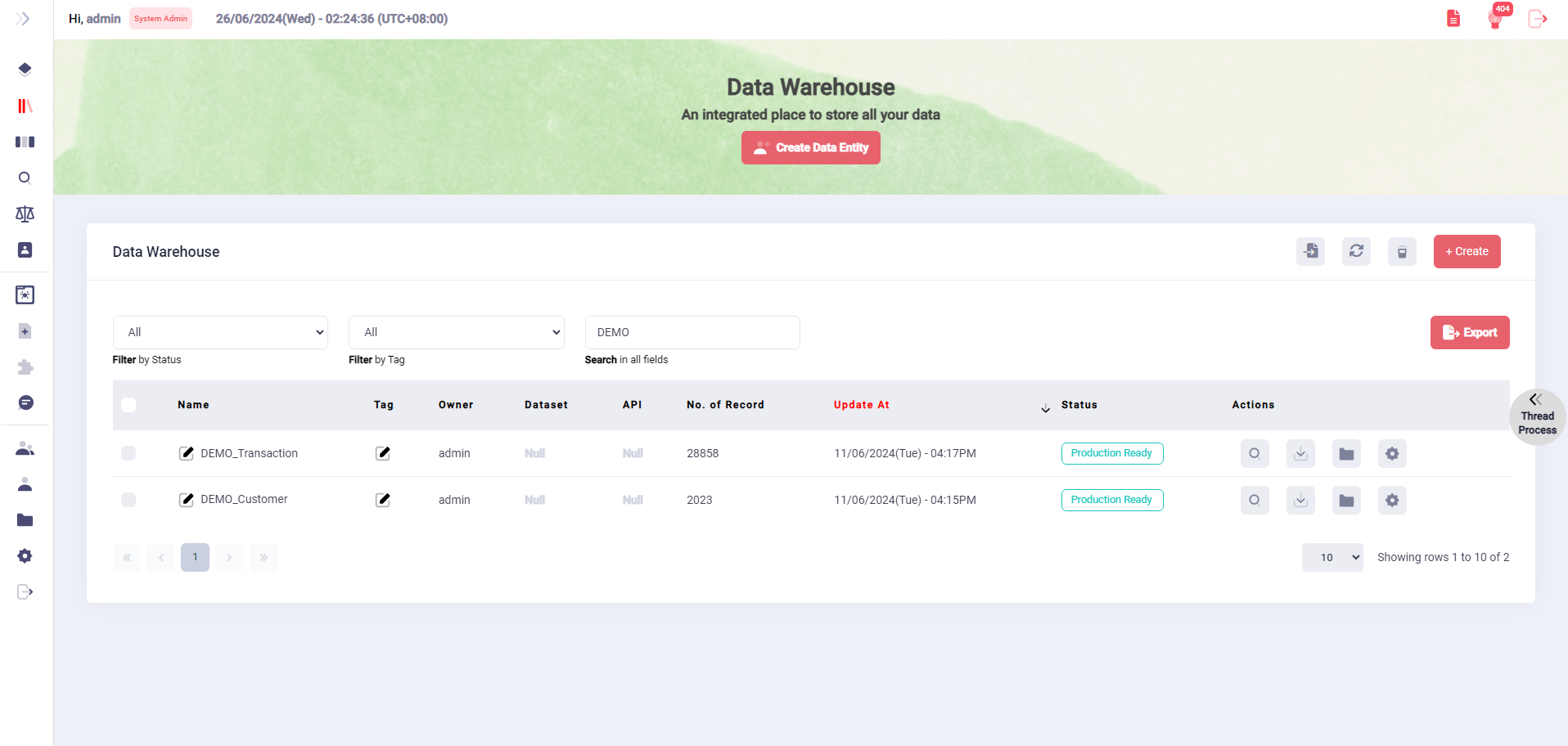
Data Warehouse
Connect with Various Data Sources
Support Various Connectors for Data Ingestion
Real Time API

Tracker API

Dataset API

File Upload

Creation and Maintenance of Data Entities
Support simplified processes to create and maintain schema structures for data organization.
Automatic Data Type Detection
Support for Diverse Data Types
Schema Versioning

Validation and Error Alerts
Large Volume of Data

Define Linking Relationships between Data Entities
Establishing clear and efficient linking relationships between data entities is crucial for maintaining data integrity and enabling complex data interactions. The following relationship types are supported.
One-to-One (1:1)

One-to-Many (1:N)

Many-to-One (N:1)
Define Access Rights of Data Entities
Establish a robust access control framework to manage permissions for data entities based on user roles through owner, editor and viewer. This framework includes:
Owner Rights

Editor Rights

Viewer Rights

Implement Secure Access Control
Regulate permissions and access based on user roles, including:
Role-Based Access Control

Audit Trails

Dynamic Access Management

Safeguard the data integrity
Throughout the whole life-cycle of the data entities-creation to purge by meticulously design data ingestion process.
Robust Data Validation

Comprehensive Monitoring

Enable Robust Archiving Mechanism
To efficiently manage old records within a data entity, This feature allows users to seamlessly move outdated entries into an archive, ensuring that the active dataset remains streamlined and performance-optimized.
Customizable Archiving Settings

Comprehensive Archive History

Searching and Retrieval Options

Programmatic Data Access
A robust framework designed to facilitate efficient data retrieval from the system, ensuring users can easily access the information they need.
Simple Query API

- Enables users to perform queries on data entities using specific criteria.
- Supports a variety of query parameters, allowing for flexible filtering and sorting of results.
- Provides comprehensive documentation and examples for ease of use, ensuring that both novice and experienced users can effectively construct queries.
Data Fetching API

- Allows for efficient reading of data entities either in batches or by specific keys.
- Optimized for high performance, enabling quick retrieval of large datasets while minimizing resource consumption.
- Supports pagination and limits to enhance the user experience, ensuring that users can manage and process data in manageable chunks.
- Includes error handling and response validation to ensure robust and reliable data access.
Data Pipeline
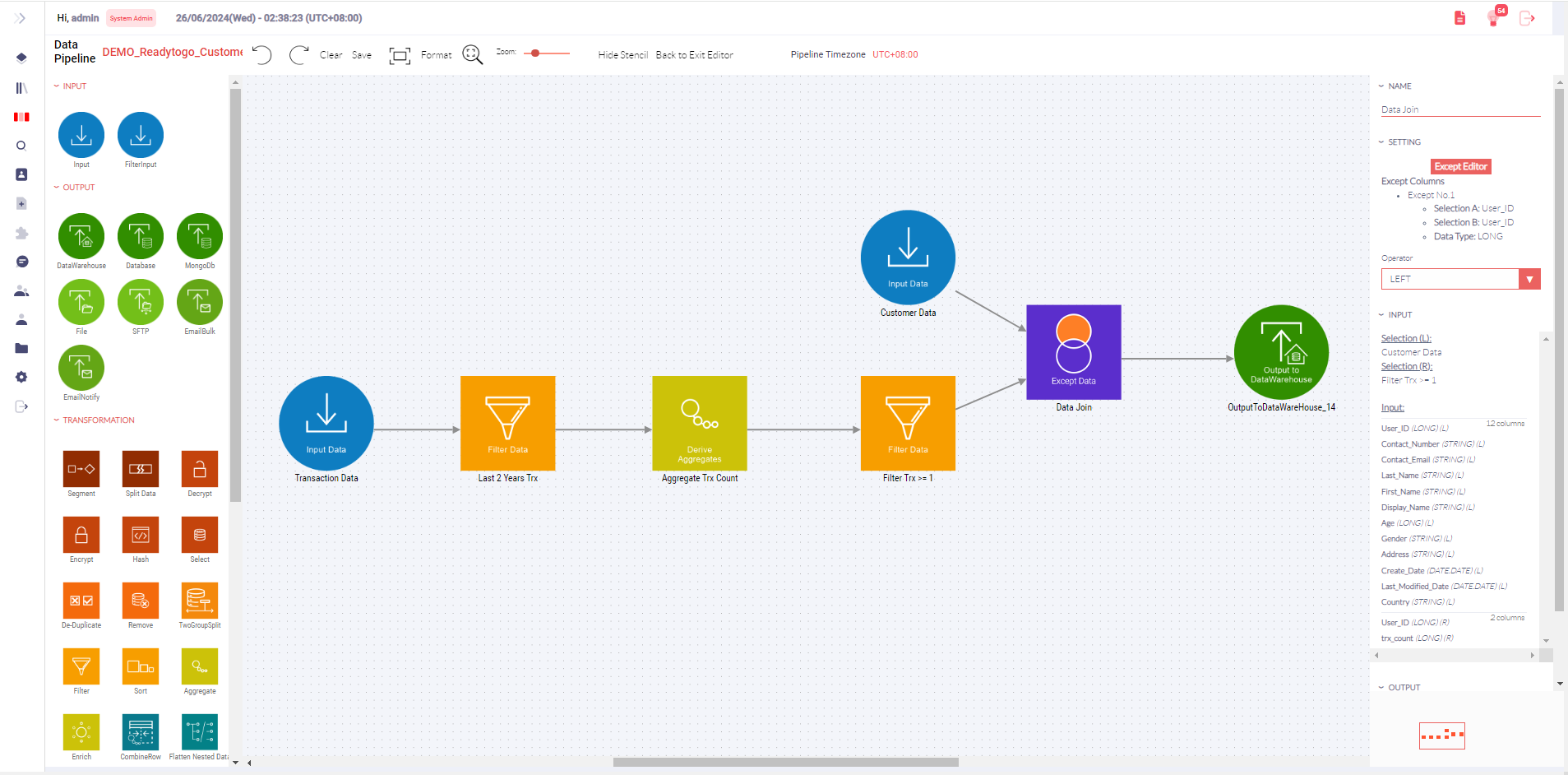
Workflow Visualization
- WYSIWYG:The Data Pipeline setup features a WYSIWYG graphical interface that enables users to create and merge data entities from both batch and streaming sources for various downstream transformations. The graphical representation of data workflows makes it easier for users to understand and manage their processes.
- Additionally, users can build ad-hoc automated data pipelines to transform multiple input data entities into ready formats using a simple drag-and-drop interface.
Creation and Maintenance of Data Pipelines

- Design and manage complex data pipelines with robust transformation and extensible data modeling components to create flexible workflows.
- Support 20+ transformation components( Filter, join, intersect, union, except, aggregate, split by group, enrich, sort, etc.) and custom-built modules(e.g. prediction, scripts), allow users each to create their pipeline without hard coding/ additional scripting.
Input and Output Management
- Versatile Data Inputs: Support various methods of data import, including manual uploads, APIs, file servers, databases, and web clicks. The Data Pipeline facilitates the transformation process by merging diverse data sources and generating formatted data.
- Versatile Data Outputs: Enable outputs to a range of applications, such as marketing automation, data visualization, AI models, and peripheral systems via APIs. The resulting data can be directed to multiple activation channels, including marketing automation, file exports, and email communications.
Batch Data Processing

- Batch and Real-Time Processing: Support both traditional batch processing and emerging real-time processing to enable immediate and continuous communication with customers.
- Batch and Streaming Data Pipelines: Facilitate the management of both batch data pipelines and streaming data pipelines, ensuring efficient handling of real-time data.
- Actionable Customer Segments: Utilize a canvas area to define unlimited actionable customer segments for marketing automation using drag-and-drop components. This allows for the identification of potential customers and those with recommended products.
Customizable Script Module

- Offers flexibility for tailored scripts to meet specific data processing needs, empowers users to create bespoke solutions aligned with unique workflows and requirements.
- Supports customization of Advanced data transformations, Automation of repetitive tasks, Integration with other systems.
- Allows for seamless customization using various scripting languages, ensures efficiency and effectiveness in data management processes as needs evolve.
Execution and Monitoring
Execution Tools

Performance Monitoring

Alerts and Notifications

Smart Query
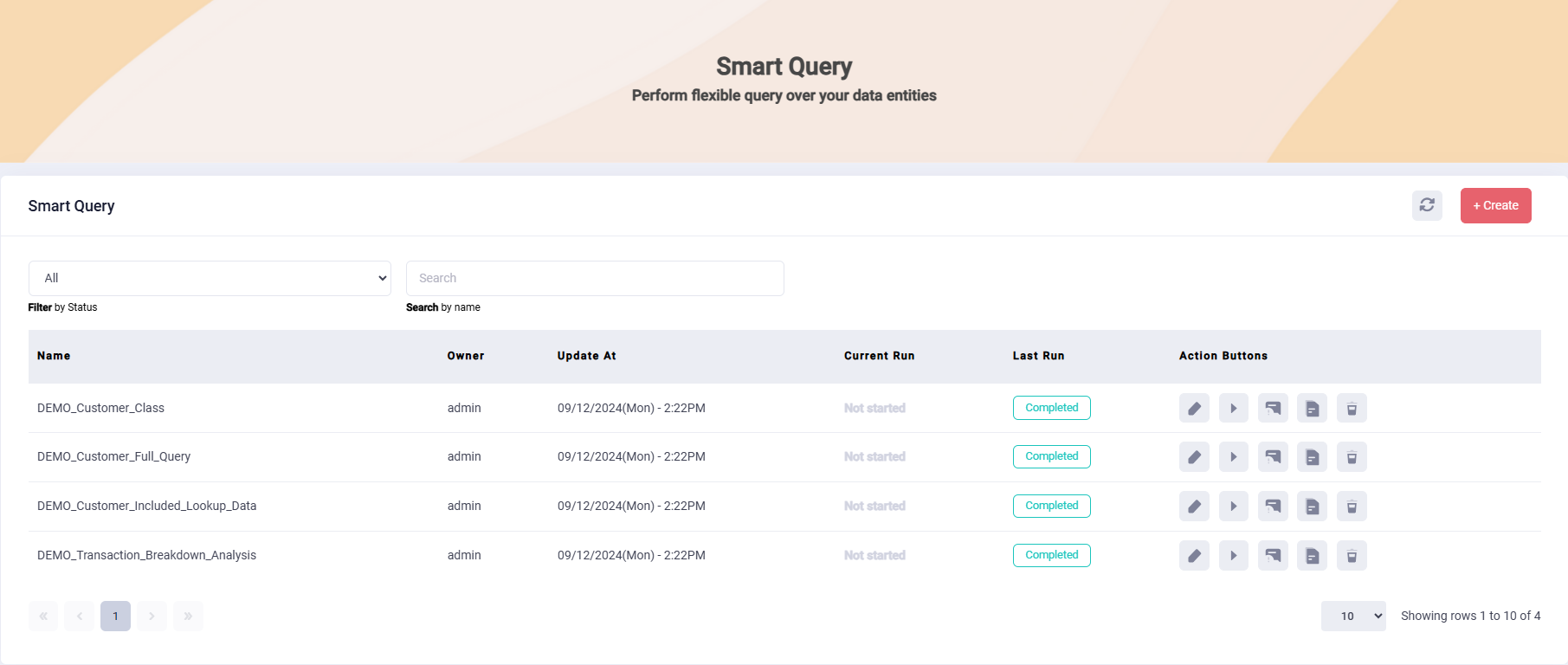
Creation and Maintenance of Smart Queries

User-Friendly Interface

Drag-and-Drop Functionality

Effortless Data Querying

Simplified Data Extraction

Ad-Hoc Query Creation
Support of Data Retrieval across Data Entities

Flexible Querying Options

Single Data Entity Queries
Linked Data Entity Queries

Versatility in Data Extraction
Practical Example
Create Custom Fields with Formulas

Custom Field Creation

Formula-Based Derivation

Example Use Case

Tailored Insights

Enhanced Data Analysis
Support of Subqueries
Subquery Functionality
Filtering and Aggregation

Practical Example

Average Salary Calculation

Simplified Query Process
Support of Input and Output Filters

Input and Output Filters

Field Specification

Pre-Filters

Post-Filters
Control and Precision
Versatile Output Options
Output Field Specification

Inclusion of Selected Fields
Data Export Options

Marketing Activation

Full Control of Exported Data
Data Comparator
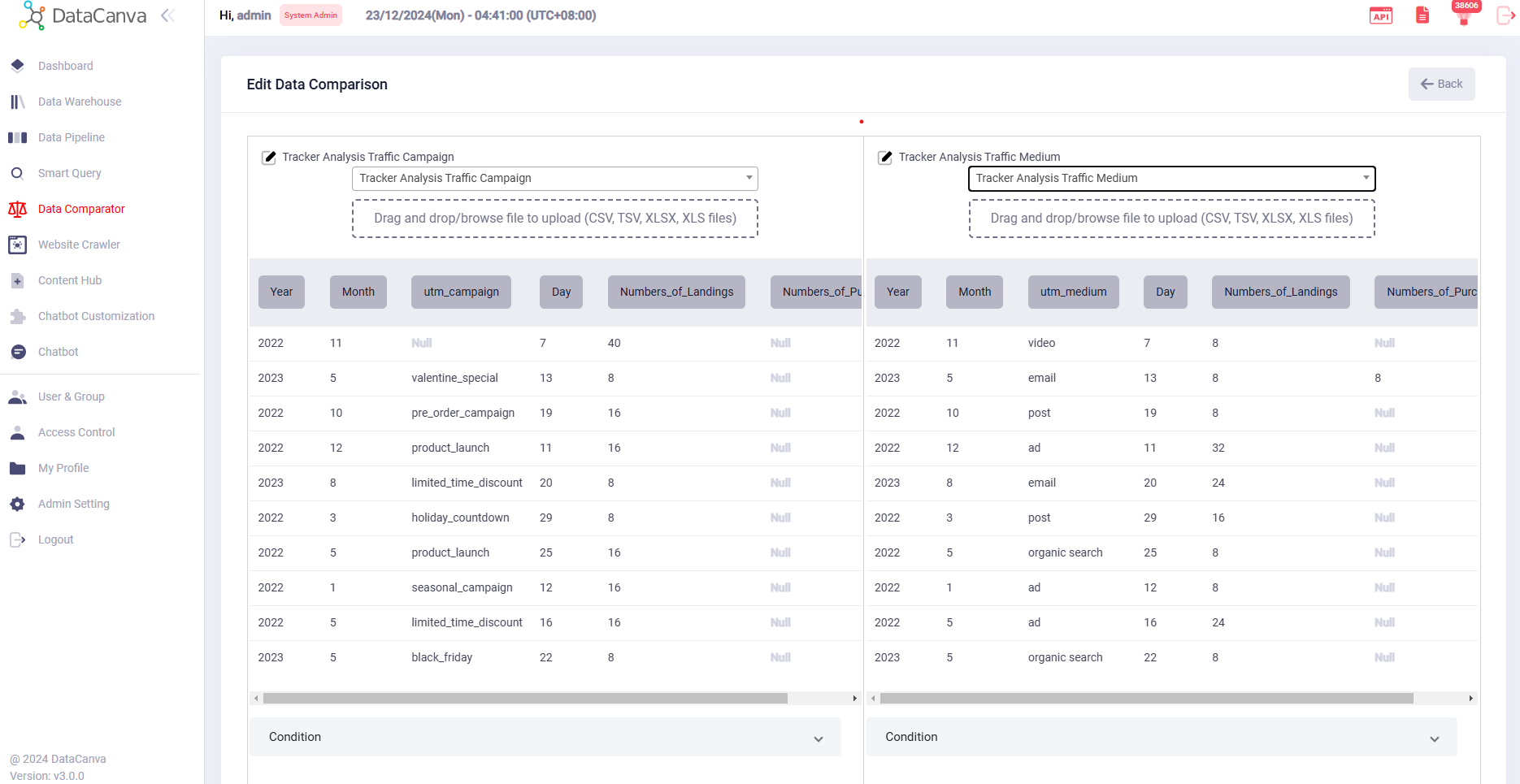

Intuitive Interface

Easily Selection

Entity Comparison
Export Functionality
Website Crawler
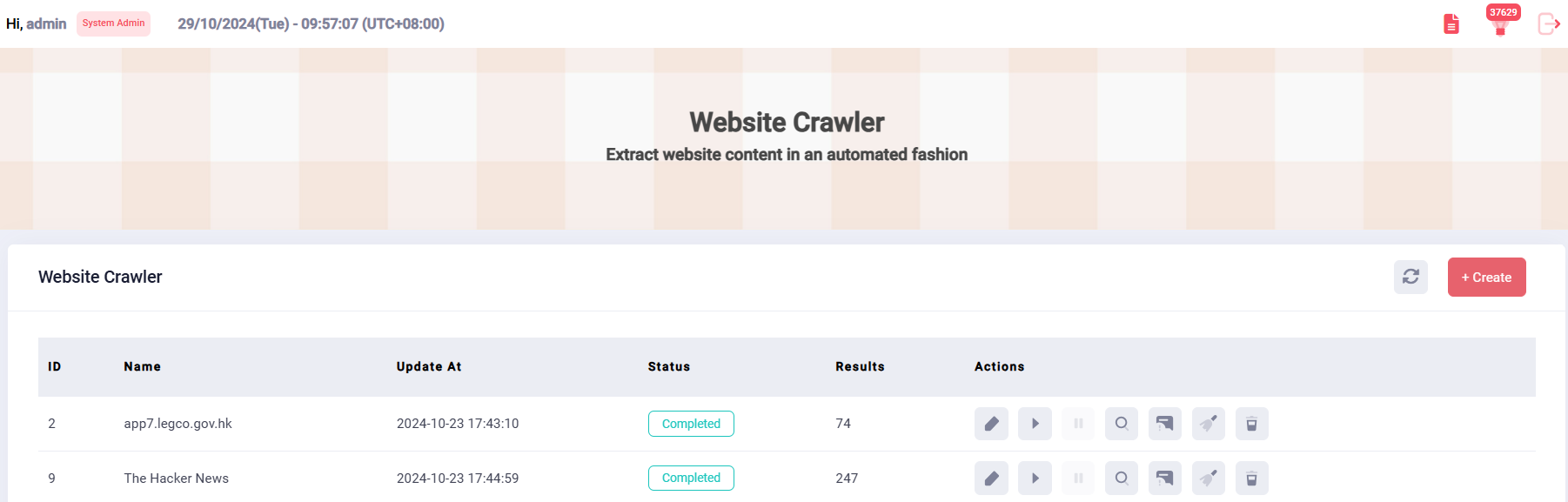
Automated Content Extraction
Flexible Scraping Field
- One-layer crawling: Ideal for scenarios involving a single-page website, allowing for straightforward extraction of content.
- Two-layer crawling: Suitable for websites with a list on the first level, enabling users to click on items to access detailed pages.
- Three-layer crawling: Designed for more complex structures, this feature supports a hierarchical approach where a category serves as the first level, followed by a list on the second level, and detailed pages at the third level.

Clear View of Crawling Process
Structured Extracted Data

Integration with Content Hub
AI-powered Chatbot
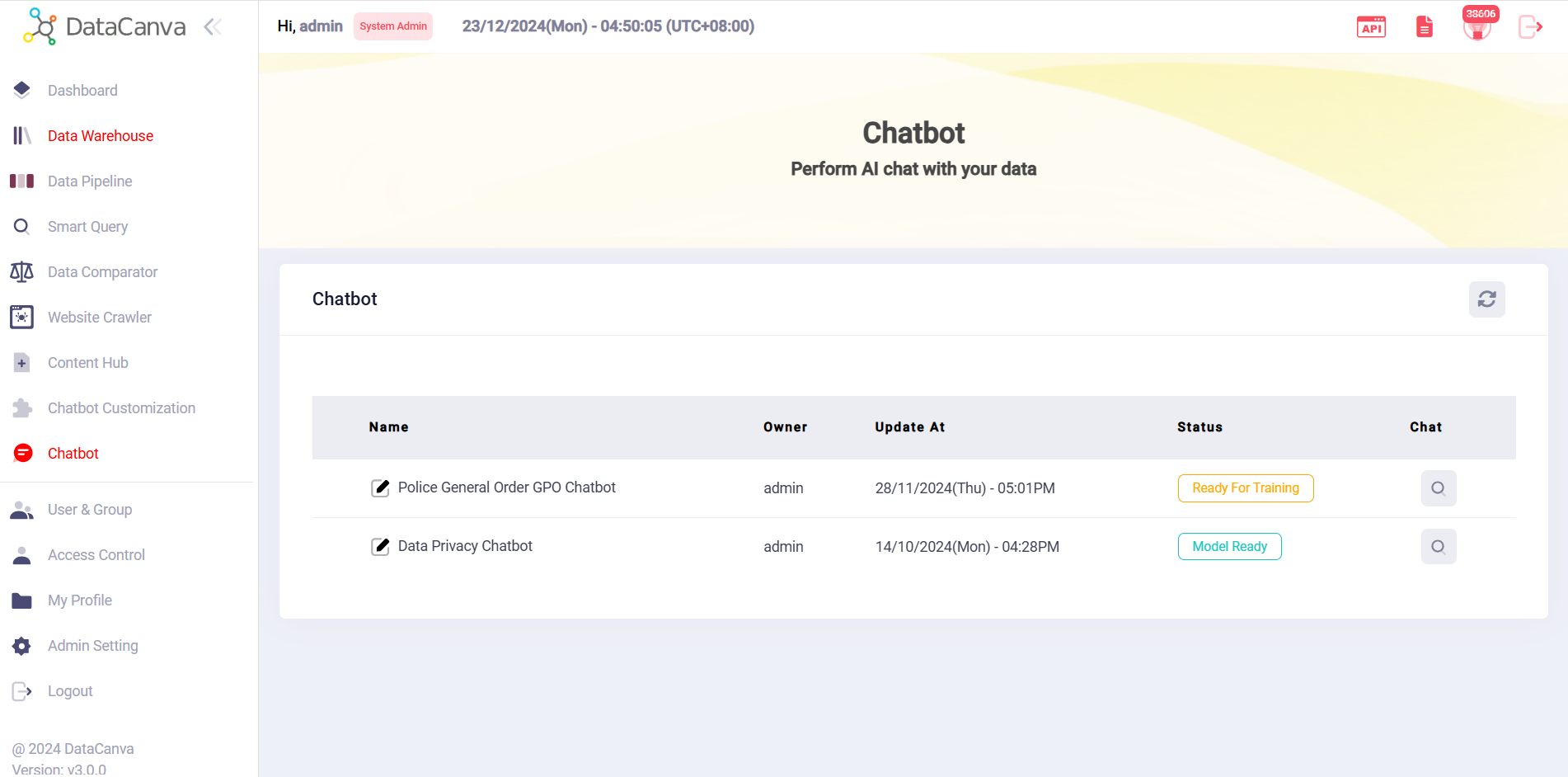
Content Hub
- Supports creating your own database in Content Hub by uploading files. These databases can be used to train your own customized chatbot.
- Supports managing your content hub, easily view, edit and delete content.

Chatbot Customization
- Link to Content Hub Database: allows users to tailor chatbot’s responses and knowledge base using users’ unique data sets which were uploaded in Content Hub.
- Various LLMs for Selection: allows users to select specific LLM to train customized chatbot.
- Status Update: allows users to know the readiness of the chatbot through various statuses.

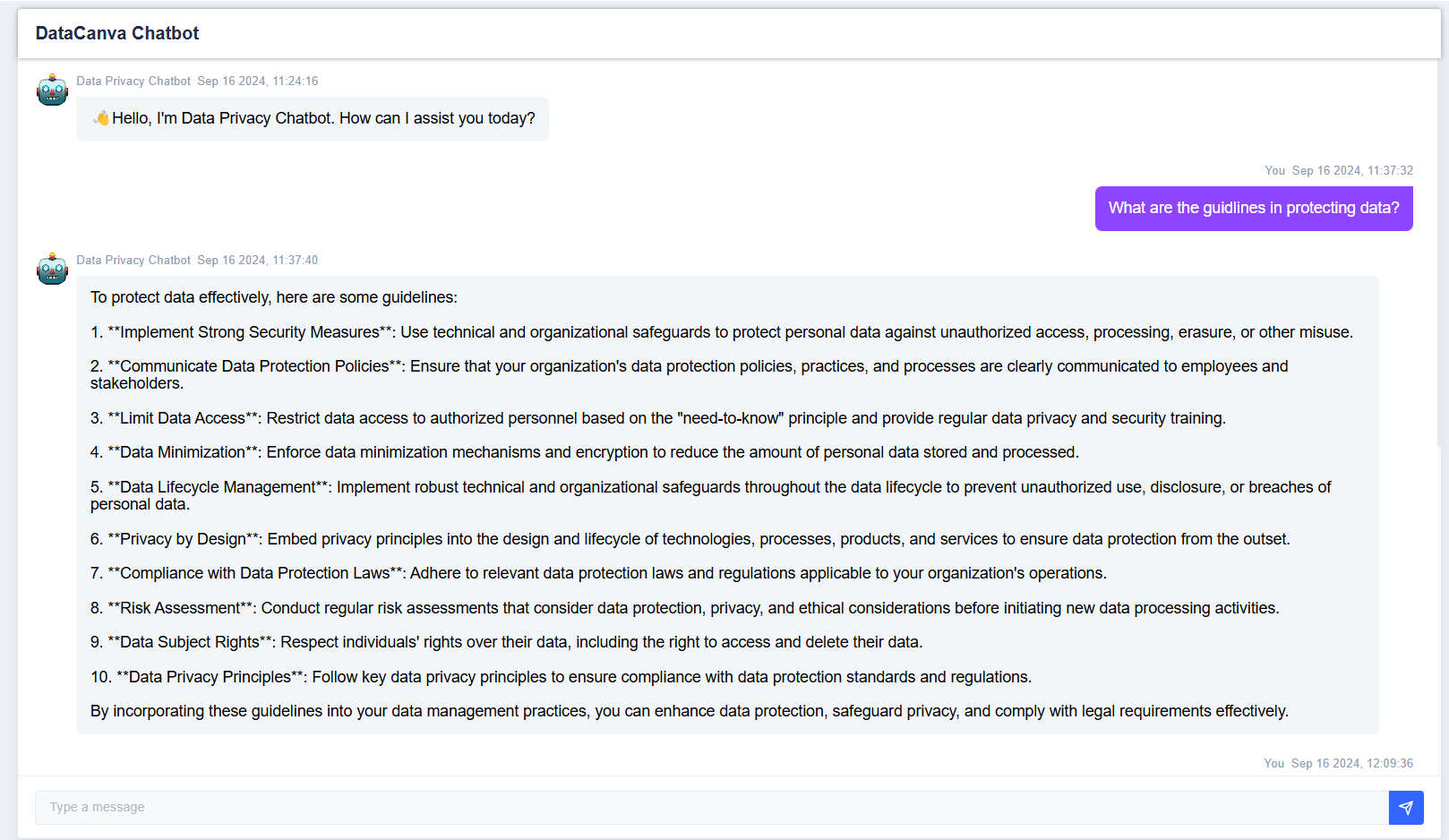
AI-Powered Conversation
- Chatbot selection: users can access any defined chatbot, the responses are context-aware out of the databases trained.
- Chat history: users can view the chat history and copy and delete individual response.
Account Management and Admin Setting
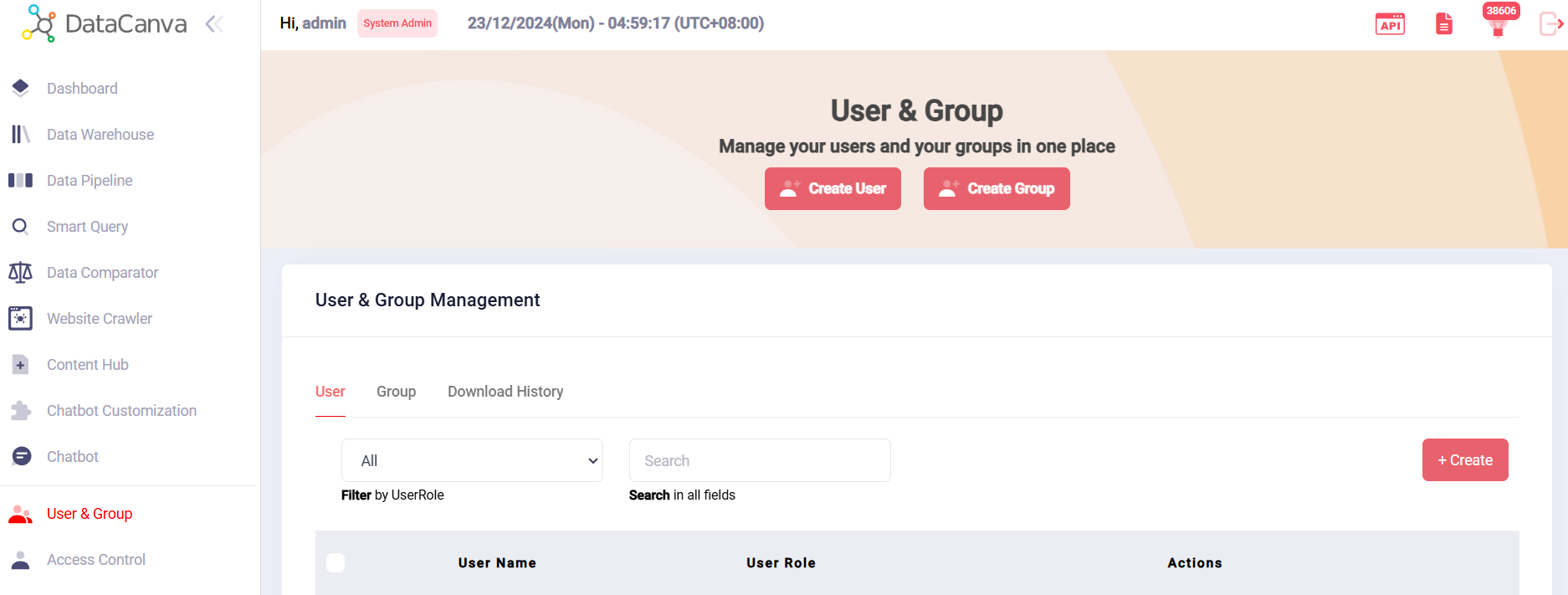

User Management

Group Management

Access Control

My Profile

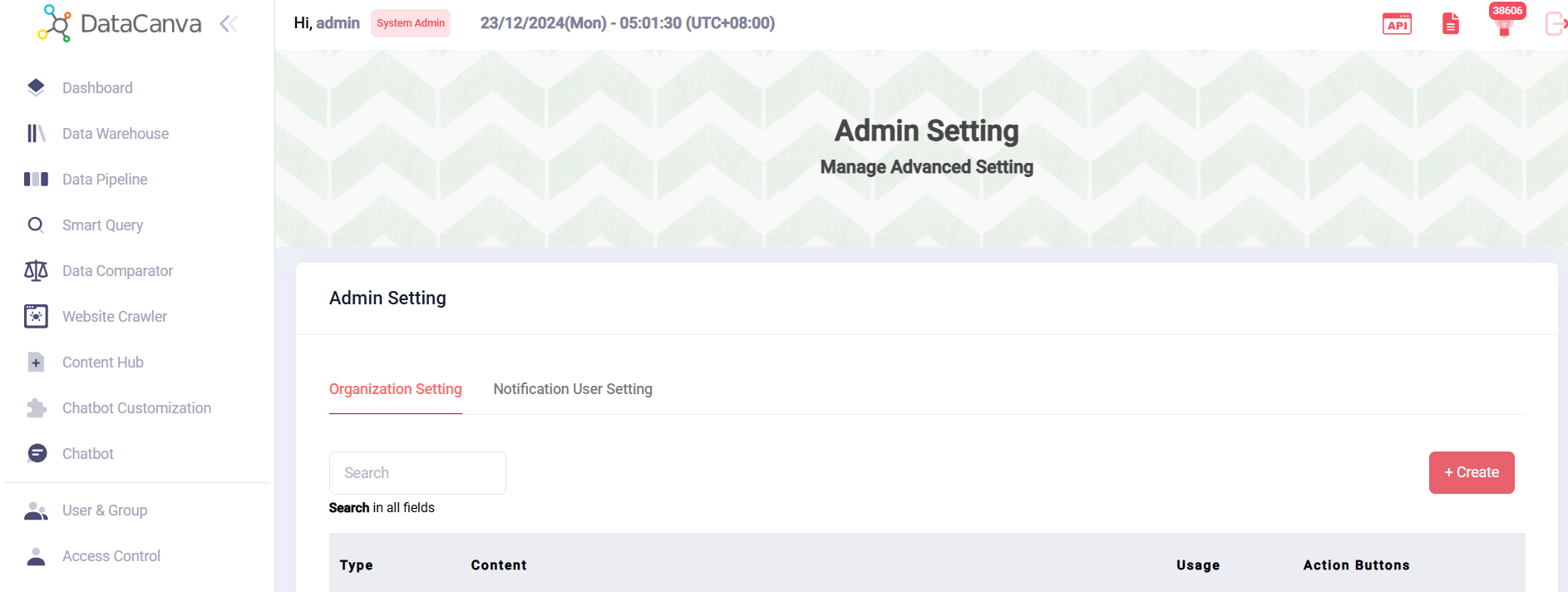
Admin Settings
Benefits of DataCanva

No-Code Data Pipelines
Centralized Data Hub
Interactive Data Exploration
Custom LLM Training
Tailored AI Responses

Robust Data Security

Holistic Data Integration