PowerLake™
Data Lake Solution
What is a Data Lake?
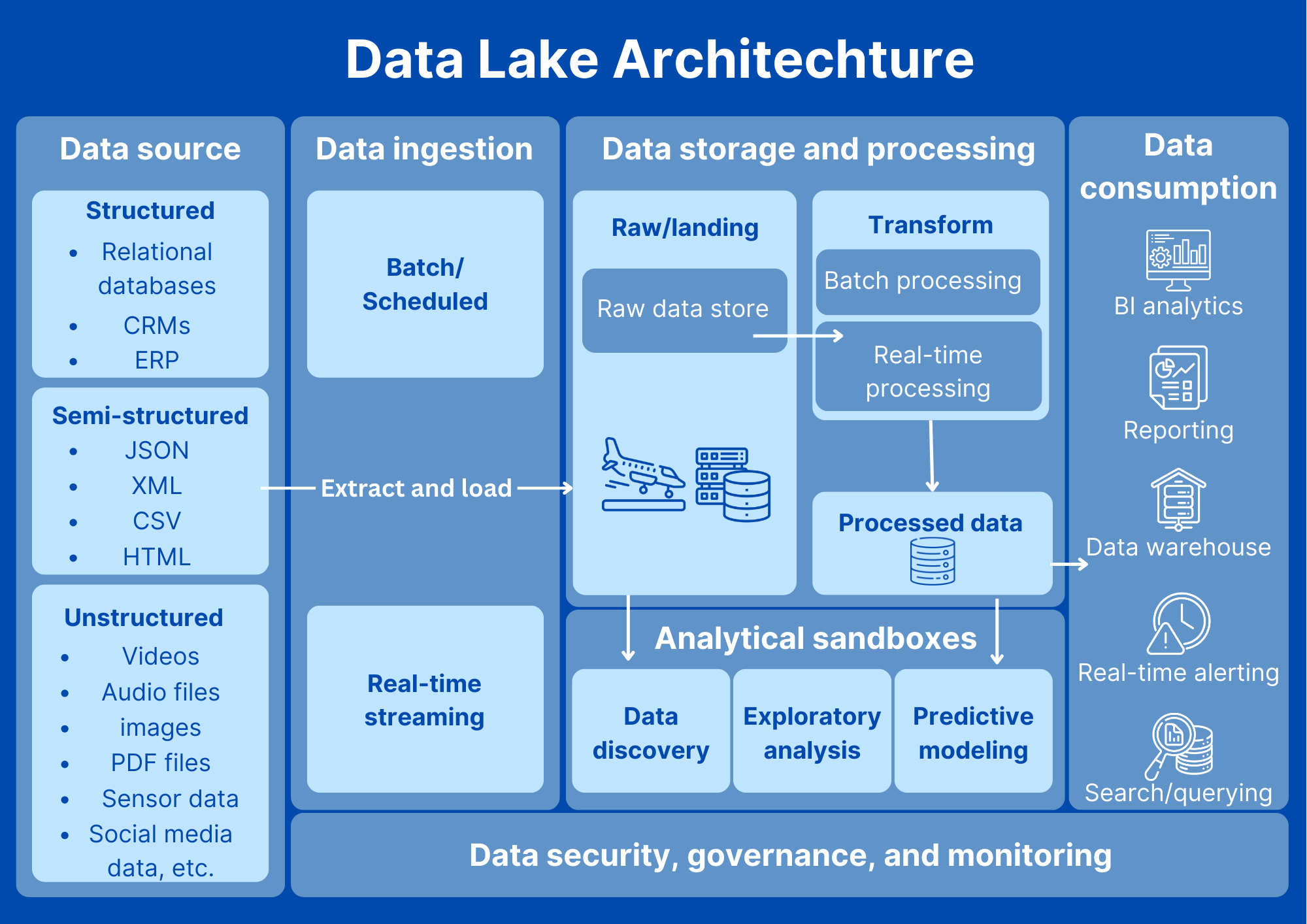
What is Our Data Lake Solution?
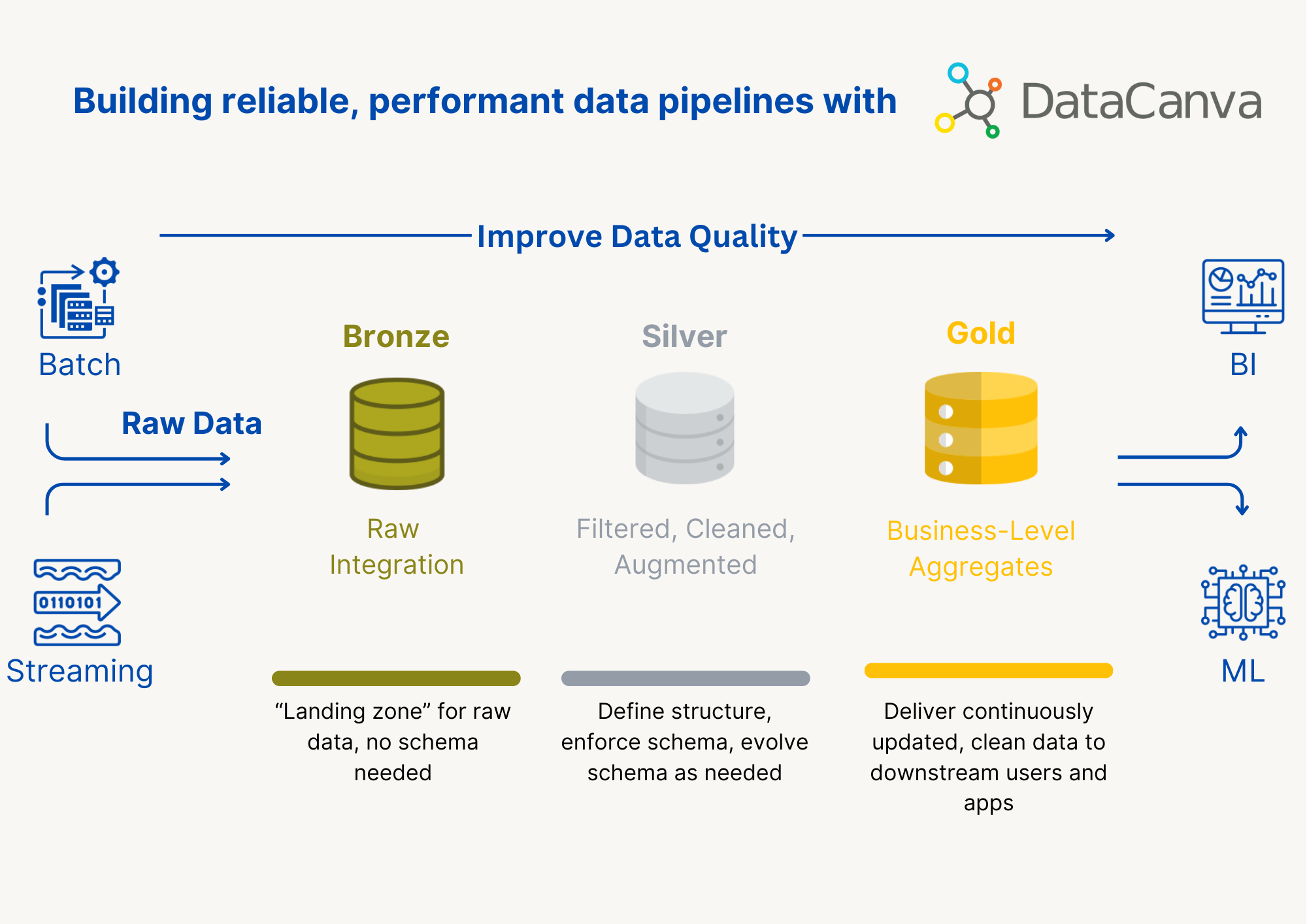
What is Medallion Architecture?

Building Data Pipelines with Medallion Architecture

Bronze Layer (Raw Data)

Silver Layer (Cleansed and Conformed Data)
Silver Layer (ELT)

Gold Layer (Curated Business-Level Tables)
Linking Data Lake with DataCanva
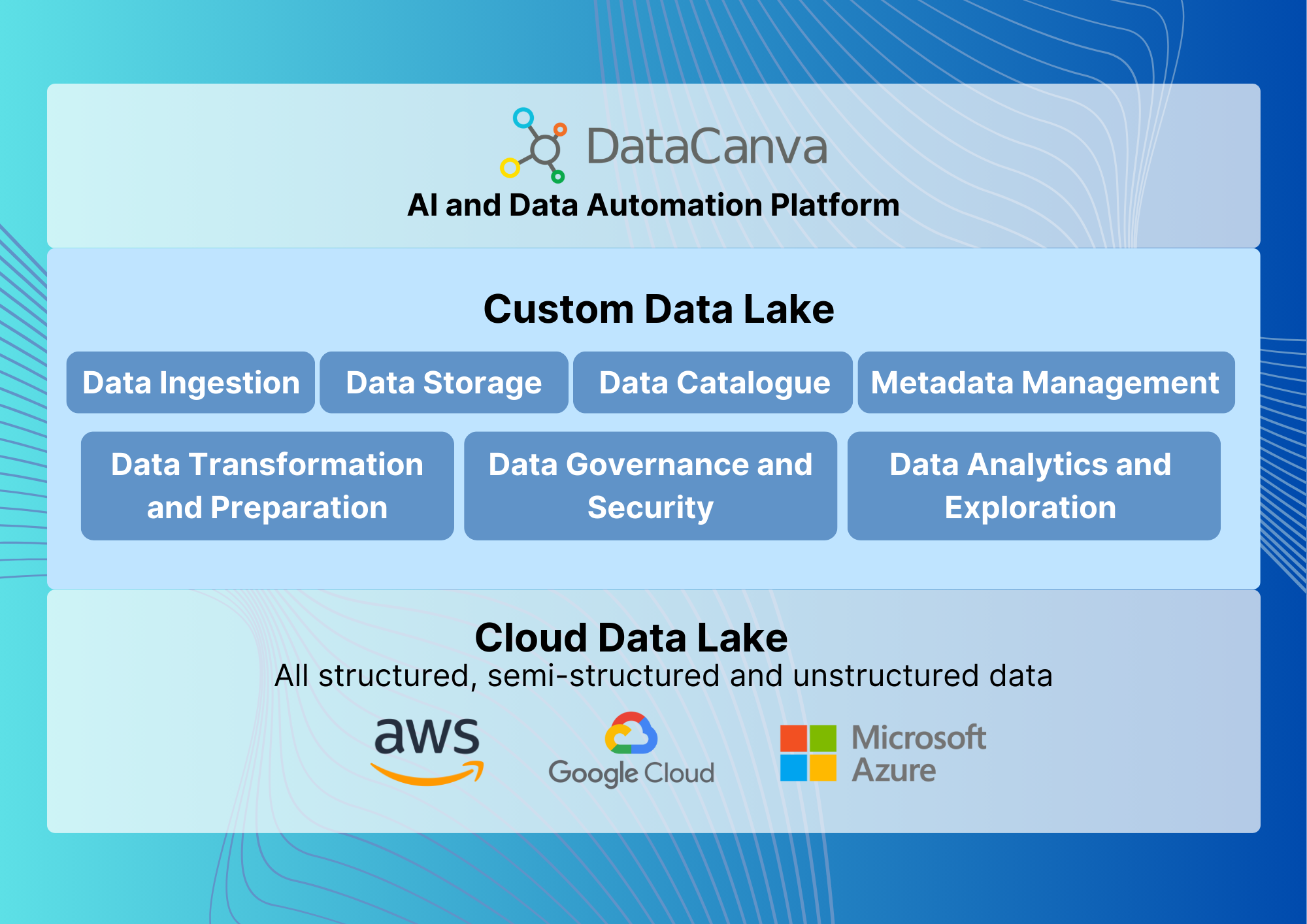
Establish a Clear Data Lake Strategy

Data Ingestion
Data Storage
Data Cataloging and Metadata Management
Data Transformation and Preparation

Data Governance and Security

Data Analytics and Exploration
Benefits of Our Data Lake Solution

Flexibility and Scalability
PowerLake™ can store vast amounts of structured, semi-structured, and unstructured data, allowing organizations to scale storage and processing capabilities as data needs grow.

Cost-Effectiveness
Using commodity hardware and cloud storage solutions, it provides a cost-effective way to store large volumes of data compared to traditional data warehouses.

Diverse Data Integration
It can ingest data from various sources, including IoT devices, social media, and enterprise applications, enabling a comprehensive view of business operations.
Rapid Data Ingestion
With a schema-on-read approach, data can be ingested quickly without the need for extensive preprocessing. This accelerates the availability of data for analysis.

Analytics and Machine Learning
This solution supports advanced analytics and machine learning by providing a rich repository of data. Analysts and data scientists can explore and experiment with data at scale.

Enhanced Data Discovery
Powerful search and discovery tools enable users to find and access relevant data easily, fostering a culture of data-driven decision-making.
Support for Real-Time Processing
Medallion Architecture Data Lake Solution can support real-time data processing through technologies like Apache Spark and Kafka, enabling timely insights and actions based on current data.

Data Governance and Security
Modern data lake architectures often include robust governance frameworks to ensure data quality, compliance, and security, helping organizations manage their data assets effectively.

Facilitates Collaboration
A centralized data repository promotes collaboration among different teams, such as data engineering, data science, and business analytics, by providing a single source of truth.
Historical Data Retention
Data lakes can retain historical data for long periods, allowing organizations to perform trend analysis and gain insights from historical patterns.

Support for Diverse Use Cases
From business intelligence to predictive analytics and data exploration, data lakes enable a variety of use cases, making them suitable for different business needs.

Integration with Existing Systems
Data lakes can complement existing data warehouses and traditional databases, allowing organizations to leverage their current investments while enhancing analytics capabilities.
Use Scenarios
Our Data Lake Solution is a robust tool designed for storing and analyzing vast amounts of data. DataCanva provides a range of services to help you build an effective data lake tailored to your business needs. Leveraging the versatile capabilities of the Data Lake Solution, built on the solid foundation of DataCanva, you can create a data lake that aligns perfectly with your organizational requirements.
Our Data Lake Solution support a wide range of scenarios, including:
Machine Learning and AI
Large datasets stored in data lakes can be utilized to build and train machine learning models, facilitating predictive analytics and AI-driven decision-making.

Real-time Analytics
Data lakes enable the processing and analysis of streaming data in real-time, allowing organizations to gain timely insights and respond instantly to events or anomalies.
IoT Data Processing
Businesses can ingest and analyze vast amounts of data from IoT devices, helping to detect patterns, identify anomalies, and optimize device performance.

Clickstream Analysis
By analyzing user behavior data from website logs, businesses can gain insights into user engagement, click patterns, and conversion rates.

Business Intelligence and Analytics
Data lakes provide a platform for conducting business intelligence and analytics on large datasets, empowering organizations to make informed decisions, uncover new opportunities, and enhance their bottom line.

Regulatory Compliance
Data lakes can store and manage information required for regulatory compliance, assisting businesses in meeting various regulations, such as the General Data Protection Regulation (GDPR).

Data Exploration
They also offer self-service analytics capabilities, enabling business users to explore, visualize, and report on data independently.