PowerOCR™
OCR Solution
What is OCR?
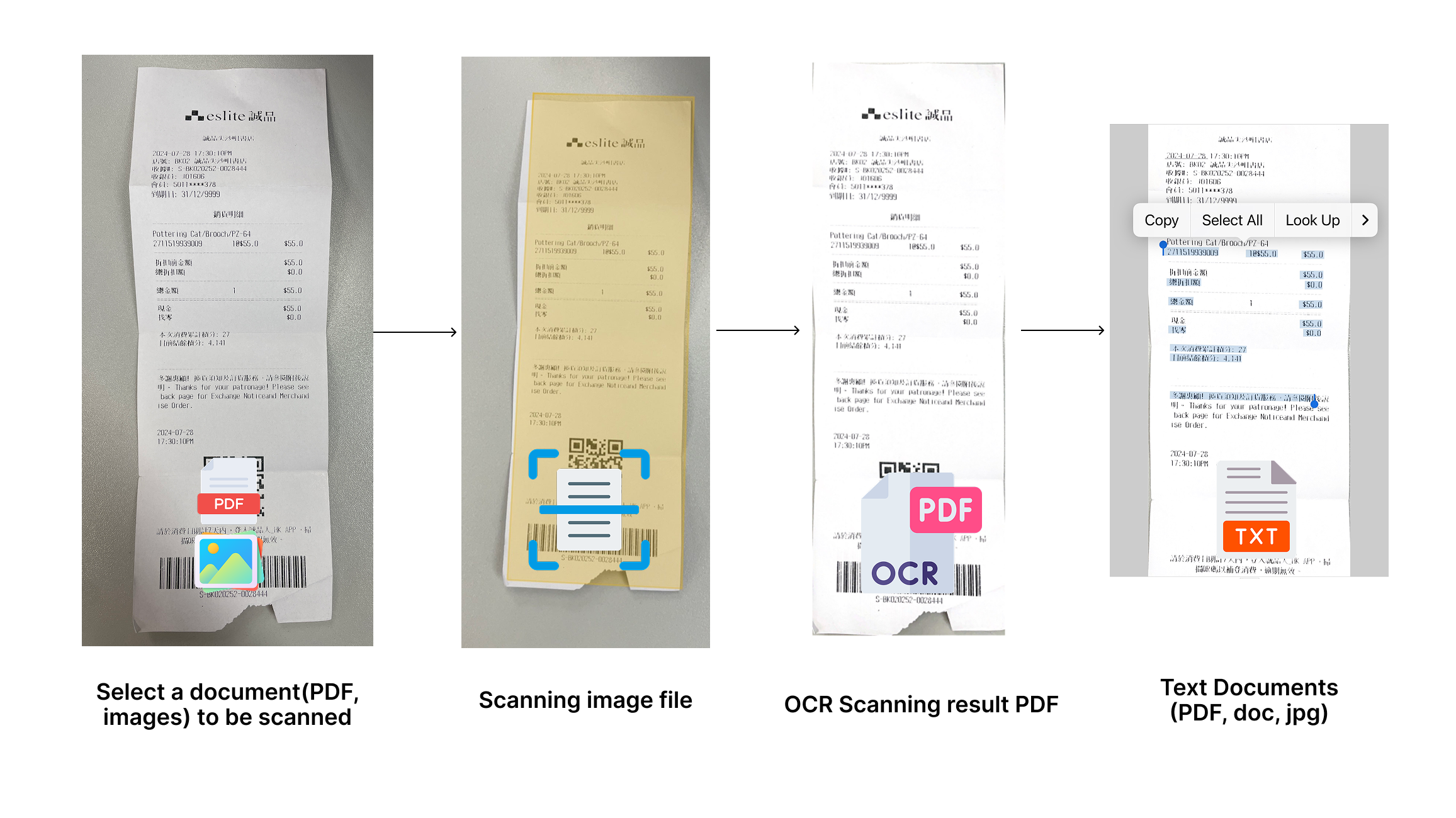
What is our OCR Solution?
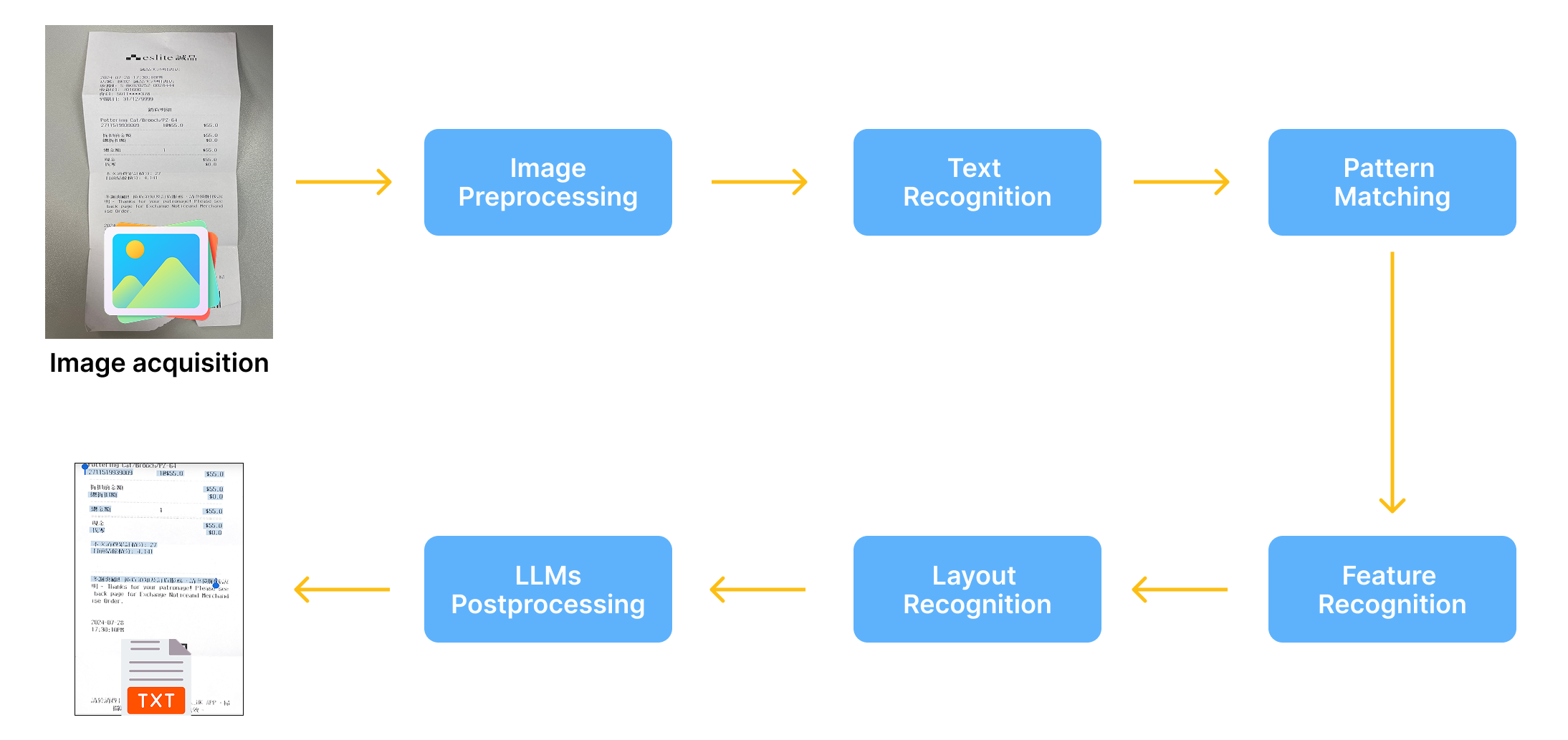

Image acquisition

Preprocessing

Text recognition
Pattern Matching

Feature recognition

Layout recognition

Postprocessing
How does this work?
1
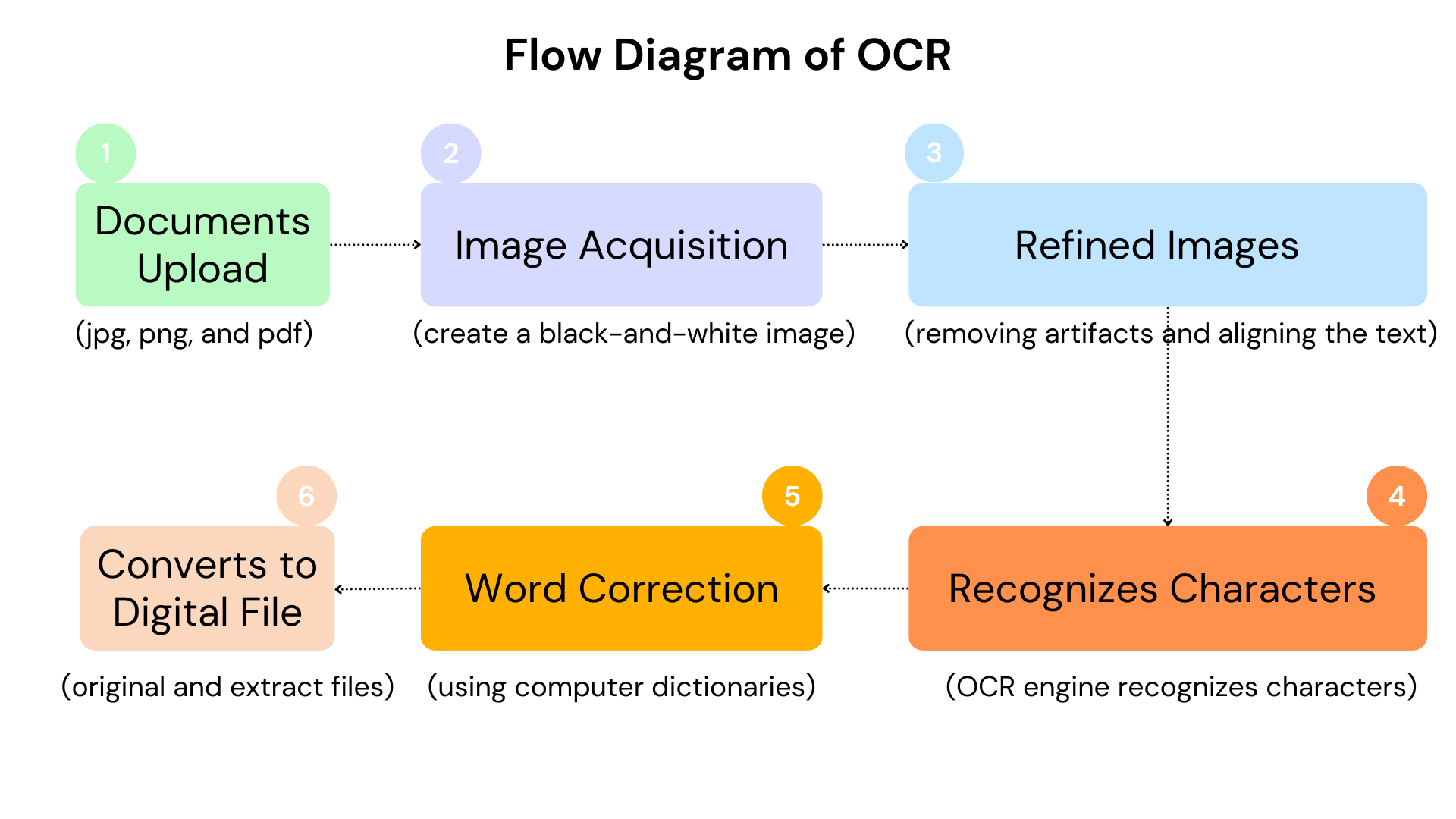
OCR can extract text from images, save it as a text file, and support various formats, including jpg, jpeg, png, bmp, tiff, and pdf.
2
The initial phase of the OCR process involves image acquisition, where a scanner captures text from a physical document and transforms it into a black-and-white image.
3
Following this, the image is refined by eliminating digital artifacts such as spots, boxes, and lines, and by aligning the text properly.
4
Once the OCR engine recognizes the characters, it translates the data into a digital file that can be easily shared, searched, edited, and copied.
5
There are various methods to enhance the output from the OCR process, such as utilizing a computer dictionary to correct nonsensical words, similar to the auto-correct feature found on many devices.
6
One of the most common applications of OCR is the conversion of printed documents into machine-readable text. After a paper document is scanned and processed through OCR, its text can be edited using word processors like Microsoft Word or Google Docs. This technology can significantly improve efficiency across various sectors, including education, finance, healthcare, logistics, and transportation, by facilitating the processing and retrieval of loan documents, patient records, insurance forms, labels, invoices, and receipts.
With this kind of OCR technology text recognition, scanned documents can be integrated into big-data systems capable of reading client information from bank statements, contracts, and other crucial printed materials. Instead of requiring employees to sift through numerous image documents and manually input data into an automated big-data processing workflow, organizations can leverage OCR to streamline this process at the data input stage.
The value of our OCR Solution
Versatility Across Document Types
- Printed Text: Easily convert printed documents into editable formats.
- Handwriting: Accurately recognize and digitize handwritten notes and forms.
- Form Recognition: Effortlessly extract data from structured forms, saving you time and effort.
- Hybrid Text and Image: Process documents featuring both text and images, ensuring no information is overlooked.

Speed and Efficiency

Accuracy and Reliability
Cost-Effective
Use scenarios for different industries

Healthcare

Finance

Legal

Education

Retail
